Hypothesis testing is a vital process in inferential statistics where the goal is to use sample data to draw conclusions about an entire population. In the testing process, you use significance levels and p-values to determine whether the test results are statistically significant.
You hear about results being statistically significant all of the time. But, what do significance levels, P values, and statistical significance actually represent? Why do we even need to use hypothesis tests in statistics?
In this post, I answer all of these questions. I use graphs and concepts to explain how hypothesis tests function in order to provide a more intuitive explanation. This helps you move on to understanding your statistical results.
Hypothesis Test Example Scenario
To start, I’ll demonstrate why we need to use hypothesis tests using an example.
A researcher is studying fuel expenditures for families and wants to determine if the monthly cost has changed since last year when the average was $260 per month. The researcher draws a random sample of 25 families and enters their monthly costs for this year into statistical software. You can download the CSV data file: FuelsCosts. Below are the descriptive statistics for this year.

We’ll build on this example to answer the research question and show how hypothesis tests work.
Descriptive Statistics Alone Won’t Answer the Question
The researcher collected a random sample and found that this year’s sample mean (330.6) is greater than last year’s mean (260). Why perform a hypothesis test at all? We can see that this year’s mean is higher by $70! Isn’t that different?
Regrettably, the situation isn’t as clear as you might think because we’re analyzing a sample instead of the full population. There are huge benefits when working with samples because it is usually impossible to collect data from an entire population. However, the tradeoff for working with a manageable sample is that we need to account for sample error.
The sampling error is the gap between the sample statistic and the population parameter. For our example, the sample statistic is the sample mean, which is 330.6. The population parameter is μ, or mu, which is the average of the entire population. Unfortunately, the value of the population parameter is not only unknown but usually unknowable. Learn more about Sampling Error.
We obtained a sample mean of 330.6. However, it’s conceivable that, due to sampling error, the mean of the population might be only 260. If the researcher drew another random sample, the next sample mean might be closer to 260. It’s impossible to assess this possibility by looking at only the sample mean. Hypothesis testing is a form of inferential statistics that allows us to draw conclusions about an entire population based on a representative sample. We need to use a hypothesis test to determine the likelihood of obtaining our sample mean if the population mean is 260.
Background information: The Difference between Descriptive and Inferential Statistics and Populations, Parameters, and Samples in Inferential Statistics
A Sampling Distribution Determines Whether Our Sample Mean is Unlikely
It is very unlikely for any sample mean to equal the population mean because of sample error. In our case, the sample mean of 330.6 is almost definitely not equal to the population mean for fuel expenditures.
If we could obtain a substantial number of random samples and calculate the sample mean for each sample, we’d observe a broad spectrum of sample means. We’d even be able to graph the distribution of sample means from this process.
This type of distribution is called a sampling distribution. You obtain a sampling distribution by drawing many random samples of the same size from the same population. Why the heck would we do this?
Because sampling distributions allow you to determine the likelihood of obtaining your sample statistic and they’re crucial for performing hypothesis tests.
Luckily, we don’t need to go to the trouble of collecting numerous random samples! We can estimate the sampling distribution using the t-distribution, our sample size, and the variability in our sample.
We want to find out if the average fuel expenditure this year (330.6) is different from last year (260). To answer this question, we’ll graph the sampling distribution based on the assumption that the mean fuel cost for the entire population has not changed and is still 260. In statistics, we call this lack of effect, or no change, the null hypothesis. We use the null hypothesis value as the basis of comparison for our observed sample value.
Sampling distributions and t-distributions are types of probability distributions.
Related posts: Sampling Distributions and Understanding Probability Distributions
Graphing our Sample Mean in the Context of the Sampling Distribution
The graph below shows which sample means are more likely and less likely if the population mean is 260. We can place our sample mean in this distribution. This larger context helps us see how unlikely our sample mean is if the null hypothesis is true (μ = 260).

The graph displays the estimated distribution of sample means. The most likely values are near 260 because the plot assumes that this is the true population mean. However, given random sampling error, it would not be surprising to observe sample means ranging from 167 to 352. If the population mean is still 260, our observed sample mean (330.6) isn’t the most likely value, but it’s not completely implausible either.
The Role of Hypothesis Tests
The sampling distribution shows us that we are relatively unlikely to obtain a sample of 330.6 if the population mean is 260. Is our sample mean so unlikely that we can reject the notion that the population mean is 260?
In statistics, we call this rejecting the null hypothesis. If we reject the null for our example, the difference between the sample mean (330.6) and 260 is statistically significant. In other words, the sample data favor the hypothesis that the population average does not equal 260.
However, look at the sampling distribution chart again. Notice that there is no special location on the curve where you can definitively draw this conclusion. There is only a consistent decrease in the likelihood of observing sample means that are farther from the null hypothesis value. Where do we decide a sample mean is far away enough?
To answer this question, we’ll need more tools—hypothesis tests! The hypothesis testing procedure quantifies the unusualness of our sample with a probability and then compares it to an evidentiary standard. This process allows you to make an objective decision about the strength of the evidence.
We’re going to add the tools we need to make this decision to the graph—significance levels and p-values!
These tools allow us to test these two hypotheses:
- Null hypothesis: The population mean equals the null hypothesis mean (260).
- Alternative hypothesis: The population mean does not equal the null hypothesis mean (260).
Related post: Hypothesis Testing Overview
What are Significance Levels (Alpha)?
A significance level, also known as alpha or α, is an evidentiary standard that a researcher sets before the study. It defines how strongly the sample evidence must contradict the null hypothesis before you can reject the null hypothesis for the entire population. The strength of the evidence is defined by the probability of rejecting a null hypothesis that is true. In other words, it is the probability that you say there is an effect when there is no effect.
For instance, a significance level of 0.05 signifies a 5% risk of deciding that an effect exists when it does not exist.
Lower significance levels require stronger sample evidence to be able to reject the null hypothesis. For example, to be statistically significant at the 0.01 significance level requires more substantial evidence than the 0.05 significance level. However, there is a tradeoff in hypothesis tests. Lower significance levels also reduce the power of a hypothesis test to detect a difference that does exist.
The technical nature of these types of questions can make your head spin. A picture can bring these ideas to life!
To learn a more conceptual approach to significance levels, see my post about Understanding Significance Levels.
Graphing Significance Levels as Critical Regions
On the probability distribution plot, the significance level defines how far the sample value must be from the null value before we can reject the null. The percentage of the area under the curve that is shaded equals the probability that the sample value will fall in those regions if the null hypothesis is correct.
To represent a significance level of 0.05, I’ll shade 5% of the distribution furthest from the null value.

The two shaded regions in the graph are equidistant from the central value of the null hypothesis. Each region has a probability of 0.025, which sums to our desired total of 0.05. These shaded areas are called the critical region for a two-tailed hypothesis test.
The critical region defines sample values that are improbable enough to warrant rejecting the null hypothesis. If the null hypothesis is correct and the population mean is 260, random samples (n=25) from this population have means that fall in the critical region 5% of the time.
Our sample mean is statistically significant at the 0.05 level because it falls in the critical region.
Related posts: One-Tailed and Two-Tailed Tests Explained, What Are Critical Values?, and T-distribution Table of Critical Values
Comparing Significance Levels
Let’s redo this hypothesis test using the other common significance level of 0.01 to see how it compares.

This time the sum of the two shaded regions equals our new significance level of 0.01. The mean of our sample does not fall within with the critical region. Consequently, we fail to reject the null hypothesis. We have the same exact sample data, the same difference between the sample mean and the null hypothesis value, but a different test result.
What happened? By specifying a lower significance level, we set a higher bar for the sample evidence. As the graph shows, lower significance levels move the critical regions further away from the null value. Consequently, lower significance levels require more extreme sample means to be statistically significant.
You must set the significance level before conducting a study. You don’t want the temptation of choosing a level after the study that yields significant results. The only reason I compared the two significance levels was to illustrate the effects and explain the differing results.
The graphical version of the 1-sample t-test we created allows us to determine statistical significance without assessing the P value. Typically, you need to compare the P value to the significance level to make this determination.
Related post: Step-by-Step Instructions for How to Do t-Tests in Excel
What Are P values?
P values are the probability that a sample will have an effect at least as extreme as the effect observed in your sample if the null hypothesis is correct.
This tortuous, technical definition for P values can make your head spin. Let’s graph it!
First, we need to calculate the effect that is present in our sample. The effect is the distance between the sample value and null value: 330.6 – 260 = 70.6. Next, I’ll shade the regions on both sides of the distribution that are at least as far away as 70.6 from the null (260 +/- 70.6). This process graphs the probability of observing a sample mean at least as extreme as our sample mean.

The total probability of the two shaded regions is 0.03112. If the null hypothesis value (260) is true and you drew many random samples, you’d expect sample means to fall in the shaded regions about 3.1% of the time. In other words, you will observe sample effects at least as large as 70.6 about 3.1% of the time if the null is true. That’s the P value!
Learn more about How to Find the P Value.
Using P values and Significance Levels Together
If your P value is less than or equal to your alpha level, reject the null hypothesis.
The P value results are consistent with our graphical representation. The P value of 0.03112 is significant at the alpha level of 0.05 but not 0.01. Again, in practice, you pick one significance level before the experiment and stick with it!
Using the significance level of 0.05, the sample effect is statistically significant. Our data support the alternative hypothesis, which states that the population mean doesn’t equal 260. We can conclude that mean fuel expenditures have increased since last year.
P values are very frequently misinterpreted as the probability of rejecting a null hypothesis that is actually true. This interpretation is wrong! To understand why, please read my post: How to Interpret P-values Correctly.
Discussion about Statistically Significant Results
Hypothesis tests determine whether your sample data provide sufficient evidence to reject the null hypothesis for the entire population. To perform this test, the procedure compares your sample statistic to the null value and determines whether it is sufficiently rare. “Sufficiently rare” is defined in a hypothesis test by:
- Assuming that the null hypothesis is true—the graphs center on the null value.
- The significance (alpha) level—how far out from the null value is the critical region?
- The sample statistic—is it within the critical region?
There is no special significance level that correctly determines which studies have real population effects 100% of the time. The traditional significance levels of 0.05 and 0.01 are attempts to manage the tradeoff between having a low probability of rejecting a true null hypothesis and having adequate power to detect an effect if one actually exists.
The significance level is the rate at which you incorrectly reject null hypotheses that are actually true (type I error). For example, for all studies that use a significance level of 0.05 and the null hypothesis is correct, you can expect 5% of them to have sample statistics that fall in the critical region. When this error occurs, you aren’t aware that the null hypothesis is correct, but you’ll reject it because the p-value is less than 0.05.
This error does not indicate that the researcher made a mistake. As the graphs show, you can observe extreme sample statistics due to sample error alone. It’s the luck of the draw!
Related posts: Statistical Significance: Definition & Meaning and Types of Errors in Hypothesis Testing
Hypothesis tests are crucial when you want to use sample data to make conclusions about a population because these tests account for sample error. Using significance levels and P values to determine when to reject the null hypothesis improves the probability that you will draw the correct conclusion.
Keep in mind that statistical significance doesn’t necessarily mean that the effect is important in a practical, real-world sense. For more information, read my post about Practical vs. Statistical Significance.
If you like this post, read the companion post: How Hypothesis Tests Work: Confidence Intervals and Confidence Levels.
You can also read my other posts that describe how other tests work:
To see an alternative approach to traditional hypothesis testing that does not use probability distributions and test statistics, learn about bootstrapping in statistics!
Share this:

Reader Interactions
Comments
Comments and Questions

For very easy concept about level of significance & p-value
1.Teacher has given a one assignment to student & asked how many error you have doing this assignment? Student reply, he can has error ≤ 5% (it is level of significance). After completion of assignment, teacher checked his error which is ≤ 5% (may be 4% or 3% or 2% even less, it is p-value) it means his results are significant. Otherwise he has error > 5% (may be 6% or 7% or 8% even more, it is p-value) it means his results are non-significant.
2. Teacher has given a one assignment to student & asked how many error you have doing this assignment? Student reply, he can has error ≤ 1% (it is level of significance). After completion of assignment, teacher checked his error which is ≤ 1% (may be 0.9% or 0.8% or 0.7% even less, it is p-value) it means his results are significant. Otherwise he has error > 1% (may be 1.1% or 1.5% or 2% even more, it is p-value) it means his results are non-significant.
p-value is significant or not mainly dependent upon the level of significance.
Hi Syed,
I think that approach helps explain how to determine statistical significance–is the p-value less than or equal to the significance level. However, it doesn’t really explain what statistical significance means. I find that comparing the p-value to the significance level is the easy part. Knowing what it means and how to choose your significance level is the harder part!
What would you say to someone who believes that a p-value higher than the level of significance (alpha) means the null hypothesis has been proven? Should you support that statement or deny it?
Hi Emmanuel,
When the p-value is greater than the significance level, you fail to reject the null hypothesis. That is different than proving it. To learn why and what it means, click the link to read a post that I’ve written that will answer your question!
Thank you so much Sir
Hi sir, your blogs are much more helpful for clearing the concepts of statistics, as a researcher I find them much more useful.
I have some quarries:
1. In many research papers I have seen authors using the statement ” means or values are statically at par at p = 0.05″ when they do some pair wise comparison between the treatments (a kind of post hoc) using some value of CD (critical difference) or we can say LSD which is calculated using alpha not using p. So with this article I think this should be alpha =0.05 or 5%, not p = 0.05 earlier I thought p and alpha are same. p it self is compared with alpha 0.05. Correct me if I am wrong.
2. When we can draw a conclusion using critical value based on critical values (CV) which is based on alpha values in different tests (e.g. in F test CV is at F (0.05, t-1, error df) when alpha is 0.05 which is table value of F and is compared with F calculated for drawing the conclusion); then why we go for p values, and draw a conclusion based on p values, even many online software do not give p value, they just mention CD (LSD)
3. can you please help me in interpreting interaction in two factor analysis (Factor A X Factor b) in Anova.
Thank You so much!
(Commenting again as I have not seen my comment in comment list; don’t know why)
Hi Himanshu,
I manually approve comments so there will be some time lag involved before they show up.
Regarding your first question, yes, you’re correct. Test results are significant at particular significance levels or alpha. They should not use p to define the significance level. You’re also correct in that you compare p to alpha.
Critical values are a different (but related) approach for determining significance. It was more common before computer analysis took off because it reduced the calculations. Using this approach in its simplest form, you only know whether a result is significant or not at the given alpha. You just determine whether the test statistic falls within a critical region to determine statistical significance or not significant. However, it is ok to supplement this type of result with the actual p-value. Knowing the precise p-value provides additional information that significant/not significant does not provide. The critical value and p-value approaches will always agree too. For more information about why the exact p-value is useful, read my post about Five Tips for Interpreting P-values.
Finally, I’ve written about two-way ANOVA in my post, How to do Two-Way ANOVA in Excel. Additionally, I write about it in my Hypothesis Testing ebook.
Thank you for your answer, Jim, I really appreciate it. I’m taking a Coursera stats course and online learning without being able to ask questions of a real teacher is not my forte!
You’re right, I don’t think I’m ready for that calculation! However, I think I’m struggling with something far more basic, perhaps even the interpretation of the t-table? I’m just not sure how you came up with the p-value as .03112, with the 24 degrees of freedom. When I pull up a t-table and look at the 24-degrees of freedom row, I’m not sure how any of those numbers correspond with your answer? Either the single tail of 0.01556 or the combined of 0.03112. What am I not getting? (which, frankly, could be a lot!!) Again, thank you SO much for your time.
Hi Sara,
Ah ok, I see! First, let me point you to several posts I’ve written about t-values and the t-distribution. I don’t cover those in this post because I wanted to present a simplified version that just uses the data in its regular units. The basic idea is that the hypothesis tests actually convert all your raw data down into one value for a test statistic, such as the t-value. And then it uses that test statistic to determine whether your results are statistically significant. To be significant, the t-value must exceed a critical value, which is what you lookup in the table. Although, nowadays you’d typically let your software just tell you.
So, read the following two posts, which covers several aspects of t-values and distributions. And then if you have more questions after that, you can post them. But, you’ll have a lot more information about them and probably some of your questions will be answered!
T-values
T-distributions
Jim, just found your website and really appreciate your thoughtful, thorough way of explaining things. I feel very dumb, but I’m struggling with p-values and was hoping you could help me.
Here’s the section that’s getting me confused:
“First, we need to calculate the effect that is present in our sample. The effect is the distance between the sample value and null value: 330.6 – 260 = 70.6. Next, I’ll shade the regions on both sides of the distribution that are at least as far away as 70.6 from the null (260 +/- 70.6). This process graphs the probability of observing a sample mean at least as extreme as our sample mean.
** I’m good up to this point. Draw the picture, do the subtraction, shade the regions. BUT, I’m not sure how to figure out the area of the shaded region — even with a T-table. When I look at the T-table on 24 df, I’m not sure what to do with those numbers, as none of them seem to correspond in any way to what I’m looking at in the problem. In the end, I have no idea how you calculated each shaded area being 0.01556.
I feel like there’s a (very simple) step that everyone else knows how to do, but for some reason I’m missing it.
Again, dumb question, but I’d love your help clarifying that.
thank you,
Sara
Hi Sara,
That’s not a dumb question at all. I actually don’t show or explain the calculations for figuring out the area. The reason for that is the same reason why students never calculate the critical t-values for their test, instead you look them up in tables or use statistical software. The common reason for all that is because calculating these values is extremely complicated! It’s best to let software do that for you or, when looking critical values, use the tables!
The principal though is that percentage of the area under the curve equals the probability that values will fall within that range.
Below is the formula for the t-distribution just in case you want to solve it yourself! 😉
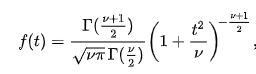
where r is the gamma function and v is the degrees of freedom.
And then, for this example, you’d need to figure out the area under the curve for particular ranges!
HI Jim, I have a question related to Hypothesis test.. in Medical imaging, there are different way to measure signal intensity (from a tumor lesion for example). I tested for the same 100 patients 4 different ways to measure tumor captation to a injected dose. So for the 100 patients, i got 4 linear regression (relation between injected dose and measured quantity at tumor sites) = so an output of 4 equations
Condition A output = -0,034308 + 0,0006602*input
Condition B output = 0,0117631 + 0,0005425*input
Condition C output = 0,0087871 + 0,0005563*input
Condition D output = 0,001911 + 0,0006255*input
My question : i want to compare the 4 methods to find the best one (compared to others) : do Hypothesis test good to me… and if Yes, i do not find test to perform it. Can you suggest me a software. I uselly used JMP for my stats… but open to other softwares…
THank for your time
G
Hi Sir,
Thank you very much for writing about this topic!
Your explanation made more sense to me about:
Why we reject Null Hypothesis when p value < significance level
Kind greetings,
Jalal
Hi Jim,
Your explanations are so helpful! Thank you. I wondered about your first graph. I see that the mean of the graph is 260 from the null hypothesis, and it looks like the standard deviation of the graph is about 31. Where did you get 31 from?
Thank you
Hi Michelle,
That is a great question. Very observant. And it gets to how these tests work. The hypothesis test that I’m illustrating here is the one-sample t-test. And this graph illustrates the sampling distribution for the t-test. T-tests use the t-distribution to determine the sampling distribution. For the t-distribution, you need to specify the degrees of freedom, which entirely defines the distribution (i.e., it’s the only parameter). For 1-sample t-tests, the degrees of freedom equal the number of observations minus 1. This dataset has 25 observations. Hence, the 24 DF you see in the graph.
Unlike the normal distribution, there is no standard deviation parameter. Instead, the degrees of freedom determines the spread of the curve. Typically, with t-tests, you’ll see results discussed in terms of t-values, both for your sample and for defining the critical regions. However, for this introductory example, I’ve converted the t-values into the raw data units (t-value * SE mean).
So, the standard deviation you’re seeing in the graph is a result of the spread of the underlying t-distribution that has 24 degrees of freedom and then applying the conversion from t-values to raw values.
Jim
Your blog is incredible.
I am having difficulty understanding why the phrase ‘as extreme as’ is required in the definition of p-value (“P values are the probability that a sample will have an effect at least as extreme as the effect observed in your sample if the null hypothesis is correct.”)
Why can’t P-Values simply be defined as “The probability of sample observation if the null hypothesis is correct?”
In your other blog titled ‘Interpreting P values’ you have explained p-values as “P-values indicate the believability of the devil’s advocate case that the null hypothesis is correct given the sample data”. I understand (or accept) this explanation. How does one move from this definition to one that contains the phrase ‘as extreme as’?
-Karan
Hi Karan,
Thanks so much for your kind words! I’m glad that my website has been helpful!
The key to understanding the “at least as extreme” wording lies in the probability plots for p-values. Using probability plots for continuous data, you can calculate probabilities, but only for ranges of values. I discuss this in my post about understanding probability distributions. In a nutshell, we need a range of values for these probabilities because the probabilities are derived from the area under a distribution curve. A single value just produces a line on these graphs rather than an area. Those ranges are the shaded regions in the probability plots. For p-values, the range corresponds to the “at least as extreme” wording. That’s where it comes from. We need a range to calculate a probability. We can’t use the single value of the observed effect because it doesn’t produce an area under the curve.
I hope that helps! I think this is a particularly confusing part of understanding p-values that most people don’t understand.
Hi Jim, thanks for the post.
Could you please clarify the following excerpt from ‘Graphing Significance Levels as Critical Regions’:
“The percentage of the area under the curve that is shaded equals the probability that the sample value will fall in those regions if the null hypothesis is correct.”
I’m not sure if I understood this correctly. If the sample value fall in one of the shaded regions, doesn’t mean that the null hypothesis can be rejected, hence that is not correct?
Thanks
Hi Thiago,
Think of it this way. There are two basic reasons for why a sample value could fall in a critical region:
You don’t know which one is true. Remember, just because you reject the null hypothesis it doesn’t mean the null is false. However, by using hypothesis tests to determine statistical significance, you control the chances of #1 occurring. The rate at which #1 occurs equals your significance level. On the hand, you don’t know the probability of the sample value falling in a critical region if the alternative hypothesis is correct (#2). It depends on the precise distribution for the alternative hypothesis and you usually don’t know that, which is why you’re testing the hypotheses in the first place!
I hope I answered the question you were asking. If not, feel free to ask follow up questions. Also, this ties into how to interpret p-values. It’s not exactly straightforward. Click the link to learn more.
Hi Jim, thank you very much for your answer. You helped me a lot!
Hi,
Thanks for this post. I’ve been learning a lot with you.
My question is regarding to lack of fit. The p-value of my lack of fit is really low, making my lack of fit significant, meaning my model does not fit well.
Is my case a “false negative”? given that my pure error is really low, making the computation of the lack of fit low. So it means my model is good.
Below I show some information, that I hope helps to clarify my question.
SumSq DF MeanSq F pValue
________ __ ________ ______ __________
Total 1246.5 18 69.25
Model 1241.7 6 206.94 514.43 9.3841e-14
. Linear 1196.6 3 398.87 991.53 1.2318e-14
. Nonlinear 45.046 3 15.015 37.326 2.3092e-06
Residual 4.8274 12 0.40228
. Lack of fit 4.7388 7 0.67698 38.238 0.0004787
. Pure error 0.088521 5 0.017704
Thank you!
Hi Laura,
As you say, a low p-value for a lack of fit test indicates that the model doesn’t fit your data adequately. This is a positive result for the test, which means it can’t be a “false negative.” At best, it could be a false positive, meaning that your data actually fit model well despite the low p-value.
I’d recommend graphing the residuals and looking for patterns. There is probably a relationship between variables that you’re not modeling correctly, such as curvature or interaction effects. There’s no way to diagnose the specific nature of the lack-of-fit problem by using the statistical output. You’ll need the graphs.
If there are no patterns in the residual plots, then your lack-of-fit results might be a false positive.
I hope this helps!
Hello Jim,
First of all, I have to say there are not many resources that explain a complicated topic in an easier manner.
My question is, how do we arrive at “if p value is less than alpha, we reject the null hypothesis.”
Is this covered in a separate article I could read?
Thanks
Shekhar
Hi Jim, terrific website, blog, and after this I’m ordering your book.
One of my biggest challenges is nomenclature, definitions, context, and formulating the hypotheses.
Here’s one I want to double-be-sure I understand:
From above you write:
”
These tools allow us to test these two hypotheses:
Null hypothesis: The population mean equals the null hypothesis mean (260).
Alternative hypothesis: The population mean does not equal the null hypothesis mean (260).
”
I keep thinking that 260 is the population mean mu, the underlying population (that we never really know exactly) and that the Null Hypothesis is comparing mu to x-bar (the sample mean of the 25 families randomly sampled w mean = sample mean = x-bar = 330.6).
So is the following incorrect, and if so, why?
Null hypothesis: The population mean mu=260 equals the null hypothesis mean x-bar (330.6).
Alternative hypothesis: The population mean mu=269 does not equal the null hypothesis mean x-bar (330.6).
And my thinking is that usually the formulation of null and alternative hypotheses is “test value” = “mu current of underlying population”, whereas I read the formulation on the webpage above to be the reverse.
Any comments appreciated. Many Thanks,
Pete
Hi Pete,
The null hypothesis states that population value equals the null value. Now, I know that’s not particularly helpful! But, the null value varies based on test and context. So, in this example, we’re setting the null value aa $260, which was the mean from the previous year. So, our null hypothesis states:
Null: the population mean (mu) = 260.
Alternative: the population mean ≠ 260.
These hypothesis statements are about the population parameter. For this type of one-sample analysis, the target or reference value you specify is the null hypothesis value. Additionally, you don’t include the sample estimate in these statements, which is the X-bar portion you tacked on at the end. It’s strictly about the value of the population parameter you’re testing. You don’t know the value of the underlying distribution. However, given the mutually exclusive nature of the null and alternative hypothesis, you know one or the other is correct. The null states that mu equals 260 while the alternative states that it doesn’t equal 260. The data help you decide, which brings us to . . .
However, the procedure does compare our sample data to the null hypothesis value, which is how it determines how strong our evidence is against the null hypothesis.
I hope I answered your question. If not, please let me know!
Really using the interpretation “In other words, you will observe sample effects at least as large as 70.6 about 3.1% of the time if the null is true”, our head seems to tie a knot. However, doing the reverse interpretation, it is much more intuitive and easier. That is, we will observe the sample effect of at least 70.6 in about 96.9% of the time, if the null is false (that is, our hypothesis is true).
Hi Ivan,
Your phrasing really isn’t any simpler. And it has the additional misfortune of being incorrect.
What you’re essentially doing is creating a one-sided confidence interval by using the p-value from a two-sided test. That’s incorrect in two ways.
So, what you need is a two-sided 95% CI (1-alpha). You could then state the results are statistically significant and you have 95% confidence that the population effect is between X and Y. If you want a lower bound as you propose, then you’ll need to use a one-sided hypothesis test with a 95% Lower Bound. That’ll give you a different value for the lower bound than the one you use.
I like confidence intervals. As I write elsewhere, I think they’re easier to understand and provide more information than a binary test result. But, you need to use them correctly!
One other point. When you are talking about p-values, it’s always under the assumption that the null hypothesis is correct. You *never* state anything about the p-value in relation to the null being false (i.e. alternative is true). But, if you want to use the type of phrasing you suggest, use it in the context of CIs and incorporate the points I cover above.
I hope this helps!
Muchas gracias profesor por compartir sus conocimientos. Un saliud especial desde Colombia.
Hey Jim
i found this really helpful . also can you help me out ?
I’m a little confused
Can you tell me if level of significance and pvalue are comparable or not and if they are what does it mean if pvalue < LS . Do we reject the null hypothesis or do we accept the null hypothesis ?
Thanks
Hi Divyanshu,
Yes, you compare the p-value to the significance level. When the p-value is less than the significance level (alpha), your results are statistically significant and you reject the null hypothesis.
I’d suggest re-reading the “Using P values and Significance Levels Together” section near the end of this post more closely. That describes the process. The next section describes what it all means.
sure.. I will use only in my class rooms that too offline with due credits to your orginal page.
I will encourage my students to visit your blog . I have purchased your eBook on Regressions….immensely useful.
Hi Narasimha, that sounds perfect. Thanks for buying my ebook as well. I’m thrilled to hear that you’ve found it to be helpful!
Dear Jim,
I have benefited a lot by your writings….Can I share the same with my students in the classroom?
Hi Narasimha,
Yes, you can certainly share with your students. Please attribute my original page. And please don’t copy whole sections of my posts onto another webpage as that can be bad with Google! Thanks!
Hello, great site and my apologies if the answer to the following question exists already.
I’ve always wondered why we put the sampling distribution about the null hypothesis rather than simply leave it about the observed mean. I can see mathematically we are measuring the same distance from the null and basically can draw the same conclusions.
For example we take a sample (say 50 people) we gather an observation (mean wage) estimate the standard error in that observation and so can build a sampling distribution about the observed mean. That sampling distribution contains a confidence interval, where say, i am 95% confident the true mean lies (i.e. in repeated sampling the true mean would reside within this interval 95% of the time).
When i use this for a hyp-test, am i right in saying that we place the sampling dist over the reference level simply because it’s mathematically equivalent and it just seems easier to gauge how far the observation is from 0 via t-stats or its likelihood via p-values?
It seems more natural to me to look at it the other way around. leave the sampling distribution on the observed value, and then look where the null sits…if it’s too far left or right then it is unlikely the true population parameter is what we believed it to be, because if the null were true it would only occur ~ 5% of the time in repeated samples…so perhaps we need to change our opinion.
Can i interpret a hyp-test that way? Or do i have a misconception?
Hi Alan,
The short answer is that, yes, you can draw the interval around the sample mean instead. And, that is, in fact, how you construct confidence intervals. The distance around the null hypothesis for hypothesis tests and the distance around the sample for confidence intervals are the same distance, which is why the results will always agree as long as you use corresponding alpha levels and confidence levels (e.g., alpha 0.05 with a 95% confidence level). I write about how this works in a post about confidence intervals.
I prefer confidence intervals for a number of reasons. They’ll indicate whether you have significant results if they exclude the null value and they indicate the precision of the effect size estimate. Corresponding with what you’re saying, it’s easier to gauge how far a confidence interval is from the null value (often zero) whereas a p-value doesn’t provide that information. See Practical versus Statistical Significance.
So, you don’t have any misconception at all! Just refer to it as a confidence interval rather than a hypothesis test, but, of course, they are very closely related.
Hi Jim,
Nice Article..
I have a question…
I read the Central limit theorem article before this article…
Coming to this article, During almost every hypothesis test, we draw a normal distribution curve assuming there is a sampling distribution (and then we go for test statistic, p value etc…). Do we draw a normal distribution curve for hypo tests because of the central limit theorem…
Thanks in advance,
Surya
Hi Surya,
These distributions are actually the t-distribution which are different from the normal distribution. T-distributions only have one parameter–the degrees of freedom. As the DF of increases, the t-distribution tightens up. Around 25 degrees of freedom, the t-distribution approximates the normal distribution. Depending on the type of t-test, this corresponds to a sample size of 26 or 27. Similarly, the sampling distribution of the means also approximate the normal distribution at around these sample sizes. With a large enough sample size, both the t-distribution and the sample distribution converge to a normal distribution regardless (largely) of the underlying population distribution. So, yes, the central limit theorem plays a strong role in this.
It’s more accurate to say that central limit theorem causes the sampling distribution of the means to converge on the same distribution that the t-test uses, which allows you to assume that the test produces valid results. But, technically, the t-test is based on the t-distribution.
Problems can occur if the underlying distribution is non-normal and you have a small sample size. In that case, the sampling distribution of the means won’t approximate the t-distribution that the t-test uses. However, the test results will assume that it does and produce results based on that–which is why it causes problems!
Dear Jim! Thank you very much for your explanation. I need your help to understand my data. I have two samples (about 300 observations) with biased distributions. I did the ttest and obtained the p-value, which is quite small. Can I draw the conclusion that the effect size is small even when the distribution of my data is not normal? Thank you
Hi Tetyana,
First, when you say that your p-value is small and that you want to “draw the conclusion that the effect size is small,” I assume that you mean statistically significant. When the p-value is low, the null hypothesis must go! In other words, you reject the null and conclude that there is a statistically significant effect–not a small effect.
Now, back to the question at hand! Yes, When you have a sufficiently large sample-size, t-tests are robust to departures from normality. For a 2-sample t-test, you should have at least 15 samples per group, which you exceed by quite a bit. So, yes, you can reliably conclude that your results are statistically significant!
You can thank the central limit theorem! 🙂
Hello Jim, I am very sorry; I have very elementary of knowledge of stats. So, would you please explain how you got a p- value of 0.03112 in the above calculation/t-test? By looking at a chart? Would you also explain how you got the information that “you will observe sample effects at least as large as 70.6 about 3.1% of the time if the null is true”?
Hi Jim,
A quick question regarding your use of two-tailed critical regions in the article above: why? I mean, what is a real-world scenario that would warrant a two-tailed test of any kind (z, t, etc.)? And if there are none, why keep using the two-tailed scenario as an example, instead of the one-tailed which is both more intuitive and applicable to most if not all practical situations. Just curious, as one person attempting to educate people on stats to another (my take on the one vs. two-tailed tests can be seen here: http://blog.analytics-toolkit.com/2017/one-tailed-two-tailed-tests-significance-ab-testing/ )
Thanks,
Georgi
Hi Georgi,
There’s the appropriate time and place for both one-tailed and two-tailed tests. I plan to write a post on this issue specifically, so I’ll keep my comments here brief.
So much of statistics is context sensitive. People often want concrete rules for how to do things in statistics but that’s often hard to provide because the answer depends on the context, goals, etc. The question of whether to use a one-tailed or two-tailed test falls firmly in this category of it depends.
I did read the article you wrote. I’ll say that I can see how in the context of A/B testing specifically there might be a propensity to use one-tailed tests. You only care about improvements. There’s probably not too much downside in only caring about one direction. In fact, in a post where I compare different tests and different options, I suggest using a one-tailed test for a similar type of casing involving defects. So, I’m onboard with the idea of using one-tailed tests when they’re appropriate. However, I do think that two-tailed tests should be considered the default choice and that you need good reasons to move to a one-tailed test. Again, your A/B testing area might supply those reasons on a regular basis, but I can’t make that a blanket statement for all research areas.
I think your article mischaracterizes some of the pros and cons of both types of tests. Just a couple of for instances. In a two-tailed test, you don’t have to take the same action regardless of which direction the results are significant (example below). And, yes, you can determine the direction of the effect in a two-tailed test. You simply look at the estimated effect. Is it positive or negative?
On the other hand, I do agree that one-tailed tests don’t increase the overall Type I error. However, there is a big caveat for that. In a two-tailed test, the Type I error rate is evenly split in both tails. For a one-tailed test, the overall Type I error rate does not change, but the Type I errors are redistributed so they all occur in the direction that you are interested in rather than being split between the positive and negative directions. In other words, you’ll have twice as many Type I errors in the specific direction that you’re interested in. That’s not good.
My big concerns with one-tailed tests are that it makes it easier to obtain the results that you want to obtain. And, all of the Type I errors (false positives) are in that direction too. It’s just not a good combination.
To answer your question about when you might want to use two-tailed tests, there are plenty of reasons. For one, you might want to avoid the situation I describe above. Additionally, in a lot of scientific research, the researchers truly are interested in detecting effects in either direction for the sake of science. Even in cases with a practical application, you might want to learn about effects in either direction.
For example, I was involved in a research study that looked at the effects of an exercise intervention on bone density. The idea was that it might be a good way to prevent osteoporosis. I used a two-tailed test. Obviously, we’re hoping that there was positive effect. However, we’d be very interested in knowing whether there was a negative effect too. And, this illustrates how you can have different actions based on both directions. If there was a positive effect, you can recommend that as a good approach and try to promote its use. If there’s a negative effect, you’d issue a warning to not do that intervention. You have the potential for learning both what is good and what is bad. The extra false-positives would’ve cause problems because we’d think that there’d be health benefits for participants when those benefits don’t actually exist. Also, if we had performed only a one-tailed test and didn’t obtain significant results, we’d learn that it wasn’t a positive effect, but we would not know whether it was actually detrimental or not.
Here’s when I’d say it’s OK to use a one-tailed test. Consider a one-tailed test when you’re in situation where you truly only need to know whether an effect exists in one direction, and the extra Type I errors in that direction are an acceptable risk (false positives don’t cause problems), and there’s no benefit in determining whether an effect exists in the other direction. Those conditions really restrict when one-tailed tests are the best choice. Again, those restrictions might not be relevant for your specific field, but as for the usage of statistics as a whole, they’re absolutely crucial to consider.
On the other hand, according to this article, two-tailed tests might be important in A/B testing!
Dear Sir, please confirm if there is an inadvertent mistake in interpretation as, “We can conclude that mean fuel expenditures have increased since last year.”
Our null hypothesis is =260. If found significant, it implies two possibilities – both increase and decrease.
Please let us know if we are mistaken here.
Many Thanks!
Hi Khalid, the null hypothesis as it is defined for this test represents the mean monthly expenditure for the previous year (260). The mean expenditure for the current year is 330.6 whereas it was 260 for the previous year. Consequently, the mean has increased from 260 to 330.7 over the course of a year. The p-value indicates that this increase is statistically significant. This finding does not suggest both an increase and a decrease–just an increase. Keep in mind that a significant result prompts us to reject the null hypothesis. So, we reject the null that the mean equals 260.
Let’s explore the other possible findings to be sure that this makes sense. Suppose the sample mean had been closer to 260 and the p-value was greater than the significance level, those results would indicate that the results were not statistically significant. The conclusion that we’d draw is that we have insufficient evidence to conclude that mean fuel expenditures have changed since the previous year.
If the sample mean was less than the null hypothesis (260) and if the p-value is statistically significant, we’d concluded that mean fuel expenditures have decreased and that this decrease is statistically significant.
When you interpret the results, you have to be sure to understand what the null hypothesis represents. In this case, it represents the mean monthly expenditure for the previous year and we’re comparing this year’s mean to it–hence our sample suggests an increase.