What is Cohens d?
Cohens d is a standardized effect size for measuring the difference between two group means. Frequently, you’ll use it when you’re comparing a treatment to a control group. It can be a suitable effect size to include with t-test and ANOVA results. The field of psychology frequently uses Cohens d.
Calculate Cohen’s d by taking the difference between two means and dividing by the data’s standard deviation. This measure reports the size of the mean difference by comparing it to the data’s variability.
![]()
Typically, you use the pooled standard deviation in the denominator, essentially the average standard deviation across both groups.
How to Interpret Cohen’s d
Cohen’s d characterizes the effect size by relating the mean difference to variability, similar to a signal-to-noise ratio. A large Cohen’s d indicates the mean difference (effect size = signal) is large compared to the variability (noise).
For example, if Group A’s Mean = 12 and Group B’s Mean = 8, and the pooled standard deviation is 2, Cohen’s d equals the following:
![]()
The mean difference is twice the variability.
However, if you have the same group means but the pooled standard deviation is 4, Cohen’s d is 1. The effect is equivalent to the variability in the data.
![]()
| Cohen’s d | Indicates Mean Difference is |
| 0.5 | Half the standard deviation. |
| 1 | Equal to the standard deviation. |
| 2 | Twice the standard deviation. |
Cohen himself suggested the following interpretations for different values.
| Cohen’s d | Effect Size |
| 0.2 | Small |
| 0.5 | Medium |
| 0.8 | Large |
What do these effect sizes look like graphically? The graph below displays a Cohen’s d = 0.8, which these criteria define as being large.
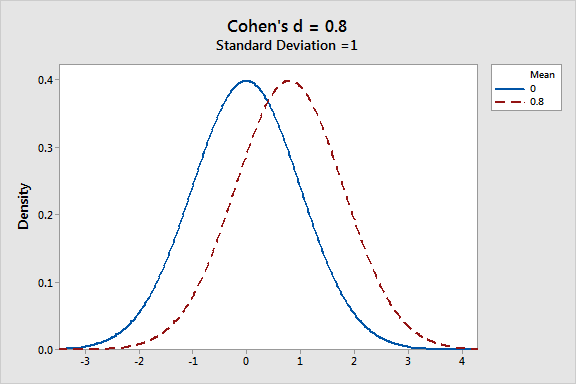
However, he also cautioned that these interpretations might not apply to all study areas.
Instead of using the generic interpretations, I recommend building a familiarity with Cohen’s d values in your subject area. As you acquire experience in your field of study, you’ll learn which effect sizes are considered small, medium, and large.
When Should You Use Cohens d?
Cohen’s d is a standardized effect size. What does that mean?
Because the Cohen’s d formula contains the natural data units in both the numerator (in the form of the mean difference) and denominator (in the standard deviation), the division process cancels out the units, producing a unitless result.
In contrast, the simple difference between means is the non-standardized effect size counterpart to Cohen’s d that does use the variable’s natural units.
Let’s explore the advantages and disadvantages of these two effects sizes to see when you should use each one!
Learn more about standardized and unstandardized effect sizes.
Disadvantages of a Unitless Measure
The primary disadvantage of using Cohen’s d is that it’s harder to interpret because it has no units. It’s harder to understand the results. What does it mean if the mean difference is 0.8 the size of the standard deviation? That’s considered large, but can you picture it?
In comparison, the mean difference is often more intuitive. For example, if Group A has a mean weight of 10kg and Group B is 5kg, the mean difference is 5kg (11lbs). You can understand that difference. The natural data units are much easier to interpret.
In general, you should use the mean difference as the simple effect size whenever possible rather than Cohen’s d.1 The units of measurement are generally meaningful, and it makes sense to use them. Evaluating practical significance is easier with the natural units. Is the mean difference large enough to be meaningful in the real world?
As Tukey2 states: “being so disinterested in our variables that we do not care about their units can hardly be desirable.”
Advantages of a Unitless Measure
However, there are situations where using Cohen’s d can be beneficial. Here’s when you should consider including it in your results.
Because Cohen’s d is unitless, it can help portray the effect size when the data units are not intrinsically meaningful or potentially confusing to your readers.
For example, many psychology studies use inventories to assess personality characteristics. Those inventory units are not inherently meaningful because they don’t relate to a tangible phenomenon. For instance, it might not be self-evident whether a 10-point difference on a specific inventory represents a small or large effect. Even if you know the answer because it’s your specialty, your readers might not!
However, Cohen’s d does not use the data units, which can help make the effect’s magnitude apparent when the natural units are not meaningful. Thanks to its unitless nature, you don’t need to be familiar with the original units to understand the results.
Additionally, its unitless nature allows you to compare your study’s findings to other studies that use a different variable with differing units.
For example, suppose two psychology experiments assess the same treatment but use two different personality indices for the outcome. Calculating the Cohen’s d for each experiment allows you to compare the results. This measure takes both studies’ findings with differing units and places them on the same standardized scale, which facilitates comparisons.
In summary, consider using Cohen’s d when the original units are not intuitively meaningful and for comparisons between studies with different variables. Meta-analyses often use it to summarize a set of findings from many studies.
References
1) Baguley T., Standardized or simple effect size: what should be reported? Br J Psychol. 2009 Aug;100(Pt 3):603-17. doi: 10.1348/000712608X377117. Epub 2008 Nov 17. PMID: 19017432.
2) Tukey, J. W. (1969). Analyzing data: Sanctification or detective work? American Psychologist, 24, 83-91.

Great website, thanks! Cohen’s d uses mean/standard deviations. However if you have (say) skewed data or data where the median/IQR are better measures, what is an appropriate tool to measure effect size?
Hi Jim, probably a silly question but if one wanted to calculate the effect size of attendance/cancellation rates pre-post health information intervention, would a statistical test need to be performed first or can cohen’s d be calculated for percentage change only?
In other words, can cohen’s d be applied to descriptive statistics or only to results of tests of group difference? I can’t seem to find the answer to this anywhere, although granted I may be looking in the wrong place!
Many thanks
Jim, in the text of a paper, is this the correct way to report the standardized mean? (P < 0.05; SMD = 0.12 [0.01 – 0.22]). or should it be 0.01, 0.22 ? Thanks!
Hi Thomas,
While the specifics can vary by field and journal, the following are general best practices when reporting SMD. I’ve often seen the following format or similar.
d = 0.12, 95% CI [0.01, 0.22], p = 0.04.
Notice that d is Cohen’s d. Typically, I’ve seen CIs represented using square brackets [] and a comma as I’ve used above. And you should report the exact p-value because that is much more meaningful than just saying it’s significant at a certain level.
Check with the journal (if that’s the destination) to see the format that recent articles have used.
Hi Jim, good post. Wouldn’t it be fair to say that Cohen’s d actually DOES have units, since the “units” are standard deviations of the pooled data? And I’ve found Cohen’s general guide about effect sizes being small (0.2), medium (0.5) and large (0.8) to not be useful at all in some fields. In medical research, a difference between groups of less than one standard deviation is generally not meaningful because the difference is within the normal range of the data. However if your treatment group has a very narrow standard deviation compared to the control group, then that’s different. Does Cohen’s d consider this difference in standard deviations between the two groups and adjust its value accordingly, or should you only use Cohen’s when the SDs are similar? And finally, how is Cohen’s d different from using Z-scores? It seems both Cohen’s d and Z-scores use standard deviation as the “unit” of measure.
Hi Jerry,
Those are all good observations and questions! Let me work through them.
As for being unitless, keep in mind that “units” in this context is shorthand for units of measurement. Literally, how are the various properties measured. As I describe in the post, the division process cancels the units out. The end result is a number that is not a unit of measurement. However, as you say, Cohen’s d is a value that relates to standard deviations. But standard deviations are not a unit of measurement. You don’t measure things in standard deviations. It’s a summary statistic.
Further, imagine a study where the outcome is in kilograms. A kilogram is a kilogram. It always refers to the same amount of mass regardless of the study or context. However, a standard deviation isn’t fixed like that. Even amongst studies that measure kg, a standard deviation of the data won’t necessarily be the same. Additionally, you can calculation standard deviations for entirely different characteristics, such as weight and length.
The point being that unlike a unit of measurement, a standard deviation does not equate to a consistent amount of a particular characteristic. It’s definitely valid to think of Cohen’s d as relating to standard deviations, but it’s not a unit of measurement.
I definitely agree about not using the general guides for Cohen’s d values that relate to small, medium, and large effects. In my own research, I’ve run into the same thing as you. Effects smaller than 1 SD are frequently not practically meaningful. I included the guidelines here because they’re frequently taught (sadly). But I also included the disclaimer about understanding effect sizes in the context of any given research area. It’s the same approach I take about schemes to describe R-squared values–I’m not a fan! I have a feeling that Cohen’s effect size interpretations might be more applicable in psychology, but I’m not sure. I also think the simple mean difference is frequently a better effect size to report, with a few exceptions.
Cohen’s d typically uses the pooled standard deviation, which is the correct form to use when you can assume that both groups are from populations that have equal variances. Pooling the data allows you to calculate a more precise estimate of the population variance. However, when you can’t assume that the two groups have equal variances, you should use the unpooled standard deviation. Below are the formulas for the pooled (Sp) and unpooled (Su) standard deviations.
Finally, Z-scores relate to describing where an individual value falls within a distribution, whereas Cohen’s d relates to the mean difference between groups. Both are similar in that they’re standardized measures but are different in terms of what they measure.