Confidence intervals and hypothesis testing are closely related because both methods use the same underlying methodology. Additionally, there is a close connection between significance levels and confidence levels. Indeed, there is such a strong link between them that hypothesis tests and the corresponding confidence intervals always agree about statistical significance.
A confidence interval is calculated from a sample and provides a range of values that likely contains the unknown value of a population parameter. To learn more about confidence intervals in general, how to interpret them, and how to calculate them, read my post about Understanding Confidence Intervals.
In this post, I demonstrate how confidence intervals work using graphs and concepts instead of formulas. In the process, I compare and contrast significance and confidence levels. You’ll learn how confidence intervals are similar to significance levels in hypothesis testing. You can even use confidence intervals to determine statistical significance.
Read the companion post for this one: How Hypothesis Tests Work: Significance Levels (Alpha) and P-values. In that post, I use the same graphical approach to illustrate why we need hypothesis tests, how significance levels and P-values can determine whether a result is statistically significant, and what that actually means.
Significance Level vs. Confidence Level
Let’s delve into how confidence intervals incorporate the margin of error. Like the previous post, I’ll use the same type of sampling distribution that showed us how hypothesis tests work. This sampling distribution is based on the t-distribution, our sample size, and the variability in our sample. Download the CSV data file: FuelsCosts.
There are two critical differences between the sampling distribution graphs for significance levels and confidence intervals–the value that the distribution centers on and the portion we shade.
The significance level chart centers on the null value, and we shade the outside 5% of the distribution.
Conversely, the confidence interval graph centers on the sample mean, and we shade the center 95% of the distribution.

The shaded range of sample means [267 394] covers 95% of this sampling distribution. This range is the 95% confidence interval for our sample data. We can be 95% confident that the population mean for fuel costs fall between 267 and 394.
Learn about Interval Notation, which is how we write confidence intervals.
Confidence Intervals and the Inherent Uncertainty of Using Sample Data
The graph emphasizes the role of uncertainty around the point estimate. This graph centers on our sample mean. If the population mean equals our sample mean, random samples from this population (N=25) will fall within this range 95% of the time.
We don’t know whether our sample mean is near the population mean. However, we know that the sample mean is an unbiased estimate of the population mean. An unbiased estimate does not tend to be too high or too low. It’s correct on average. Confidence intervals are correct on average because they use sample estimates that are correct on average. Given what we know, the sample mean is the most likely value for the population mean.
Given the sampling distribution, it would not be unusual for other random samples drawn from the same population to have means that fall within the shaded area. In other words, given that we did, in fact, obtain the sample mean of 330.6, it would not be surprising to get other sample means within the shaded range.
If these other sample means would not be unusual, we must conclude that these other values are also plausible candidates for the population mean. There is inherent uncertainty when using sample data to make inferences about the entire population. Confidence intervals help gauge the degree of uncertainty, also known as the margin of error.
Related post: Sampling Distributions
Use my Confidence Interval Calculator to find the CI for your data!
Confidence Intervals and Statistical Significance
If you want to determine whether your hypothesis test results are statistically significant, you can use either P-values with significance levels or confidence intervals. These two approaches always agree.
The relationship between the confidence level and the significance level for a hypothesis test is as follows:
Confidence level = 1 – Significance level (alpha)
For example, if your significance level is 0.05, the equivalent confidence level is 95%.
Both of the following conditions represent statistically significant results:
- The P-value in a hypothesis test is smaller than the significance level.
- The confidence interval excludes the null hypothesis value.
Further, it is always true that when the P-value is less than your significance level, the interval excludes the value of the null hypothesis.
In the fuel cost example, our hypothesis test results are statistically significant because the P-value (0.03112) is less than the significance level (0.05). Likewise, the 95% confidence interval [267 394] excludes the null hypotheses value (260). Using either method, we draw the same conclusion.
Hypothesis Testing and Confidence Intervals Always Agree
The hypothesis testing and confidence interval results always agree. To understand the basis of this agreement, remember how confidence levels and significance levels function:
- A confidence level determines the distance between the sample mean and the confidence limits.
- A significance level determines the distance between the null hypothesis value and the critical regions.
Both of these concepts specify a distance from the mean to a limit. Surprise! These distances are precisely the same length.
A 1-sample t-test calculates this distance as follows:
The critical t-value * standard error of the mean
Interpreting these statistics goes beyond the scope of this article. But, using this equation, the distance for our fuel cost example is $63.57.
P-value and significance level approach: If the sample mean is more than $63.57 from the null hypothesis mean, the sample mean falls within the critical region, and the difference is statistically significant.
Confidence interval approach: If the null hypothesis mean is more than $63.57 from the sample mean, the interval does not contain this value, and the difference is statistically significant.
Of course, they always agree!
The two approaches always agree as long as the same hypothesis test generates the P-values and confidence intervals and uses equivalent confidence levels and significance levels.
Related posts: Standard Error of the Mean and Critical Values
I Really Like Confidence Intervals!
In statistics, analysts often emphasize using hypothesis tests to determine statistical significance. Unfortunately, a statistically significant effect might not always be practically meaningful. For example, a significant effect can be too small to be important in the real world. Confidence intervals help you navigate this issue!
Similarly, the margin of error in a survey tells you how near you can expect the survey results to be to the correct population value.
Learn more about this distinction in my post about Practical vs. Statistical Significance.
Learn how to use confidence intervals to compare group means!
Finally, learn about bootstrapping in statistics to see an alternative to traditional confidence intervals that do not use probability distributions and test statistics. In that post, I create bootstrapped confidence intervals.
Reference
Neyman, J. (1937). Outline of a Theory of Statistical Estimation Based on the Classical Theory of Probability. Philosophical Transactions of the Royal Society A. 236 (767): 333–380.

Jim,
I am helping my Physics students use their data to determine whether they can say momentum is conserved. One of the columns in their data chart was change in momentum and ultimately we want this to be 0. They are obviously not getting zero from their data because of outside factors. How can I explain to them that their data supports or does not support conservation of momentum using statistics? They are using a 95% confidence level. Again, we want the change in momentum to be 0. Thank you.
Hi Lars,
I can see several complications with that approach and also my lack of familiarity with the subject area limits what I can say. But here are some considerations.
For starters, I’m unsure whether the outside factors you mention bias the results systematically from zero or just add noise (variability) to the data (but not systematically bias).
If the outside factors bias the results to a non-zero value, then you’d expect the case where larger samples will be more likely to produce confidence intervals that exclude zero. Indeed, only smaller samples sizes might produce CIs that include zero, but that would only be due to the relative lack of precision associated with small sample sizes. In other words, limited data won’t be able to distinguish the sample value from zero even though, given the bias of the outside factors, you’d expect a non-zero value. In other words, if the bias exists, the larger samples will detect the non-zero values correctly while smaller samples might miss it.
If the outside factors don’t bias the results but just add noise, then you’d expect that both small and larger samples will include zero. However, you still have the issue of precision. Smaller samples will include zero because they’re relatively wider intervals. Larger samples should include zero but have narrower intervals. Obviously, you can trust the larger samples more.
In hypothesis testing, when you fail to reject the null, as occurs in the unbiased discussion above, you’re not accepting the null. Click the link to read about that. Failing to reject the null does not mean that the population value equals the hypothesized value (zero in your case). That’s because you can fail to reject the null due to poor quality data (high noise and/or small sample sizes). And you don’t want to draw conclusions based on poor data.
There’s a class of hypothesis testing called equivalence testing that you should use in this case. It flips the null and alternative hypotheses so that the test requires you to collect strong evidence to show that the sample value equals the null value (again, zero in your case). I don’t have a post on that topic (yet), but you can read the Wikipedia article about Equivalence Testing.
I hope that helps!
Hi Jim,
Thank you very much.
When training a machine learning model using bootstrap, in the end we will have the confidence interval of accuracy.
How can I say that this result is statistically significant?
Do I have to convert the confidence interval to p-values first and if p-value is less than 0.05, then it is statistically significant?
Hi Loukas,
As I mention in this article, you determine significance using a confidence interval by assessing whether it excludes the null hypothesis value. When it excludes the null value, your results are statistically significant.
Dear Jim,
Thanks for this post.
I am new to hypothesis testing and would like to ask you how we know that the null hypotheses value is equal to 260.
Thank you.
Kind regards,
Loukas
Hi Loukas,
For this example, the null hypothesis is 260 because that is the value from the previous year and they wanted to compare the current year to the previous year. It’s defined as the previous year value because the goal of the study was to determine whether it has changed since last year.
In general, the null hypothesis will often be a meaningful target value for the study based on their knowledge, such as this case. In other cases, they’ll use a value that represents no effect, such as zero.
I hope that helps clarify it!
Hello, Mr. Jim Frost.
Thank you for publishing precise information about statistics, I always read your posts and bought your excellent e-book about regression! I really learn from you.
I got a couple of questions about the confidence level of the confidence intervals. Jacob Cohen, in his article “things I’ve learned (so far)” said that, in his experience, the most useful and informative confidence level is 80%; other authors state that if that level is below 90% it would be very hard to compare across results, as it is uncommon.
My first question is: in exploratory studies, with small samples (for example, N=85), if one wishes to generate correlational hypothesis for future research, would it be better to use a lower confidence level? What is the lowest level you would consider to be acceptable? I ask that because of my own research now, and with a sample size 85 (non-probabilistic sampling) I know all I can do is generate some hypothesis to be explored in the future, so I would like my confidence intervals to be more informative, because I am not looking forward to generalize to the population.
My second question is: could you please provide an example of an appropriate way to describe the information about the confidence interval values/limits, beyond the classic “it contains a difference of 0; it contains a ratio of 1”.
I would really appreciate your answers.
Greetings from Peru!
Hi Victor,
Thanks so much for your kind words and for supporting my regression ebook! I’m glad it’s been helpful! 🙂
On to your questions!
I haven’t read Cohen’s article, so I don’t understand his rationale. However, I’m extremely dubious of using a confidence level as low as 80%. Lowering the confidence level will create a narrower CI, which looks good. However, it comes at the expense of dramatically increasing the likelihood that the CI won’t contain the correct population value! My position is to leave the confidence level at 95%. Or, possibly lower it to 90%. But, I wouldn’t go further. Your CI will be wider, but that’s OK. It’s reflecting the uncertainty that truly exists in your data. That’s important. The problem with lowering the CIs is that it makes your results appear more precise than they actually are.
When I think of exploratory research, I think of studies that are looking at tendencies or trends. Is the overall pattern of results consistent with theoretical expectations and justify further research? At that stage, it shouldn’t be about obtaining statistically significant results–at least not as the primary objective. Additionally, exploratory research can help you derive estimated effect sizes, variability, etc. that you can use for power calculations. A smaller, exploratory study can also help you refine your methodology and not waste your resources by going straight to a larger study that, as a result, might not be as refined as it would without a test run in the smaller study. Consequently, obtaining significant results, or results that look precise when they aren’t, aren’t the top priorities.
I know that lowering the confidence level makes your CI look more information but that is deceptive! I’d resist that temptation. Maybe go down to 90%. Personally, I would not go lower.
As for the interpretation, CIs indicate the likely range that a population parameter is likely to fall within. The parameter can be a mean, effect size, ratio, etc. Often times, you as the researcher are hoping the CI excludes an important value. For example, if the CI is of the effect size, you want the CI to exclude zero (no effect). In that case, you can say that there is unlikely to be no effect in the population (i.e., there probably is a non-zero effect in the population). Additionally, the effect size is likely to be within this range. Other times, you might just want to know the range of values itself. For example, if you have a CI for the mean height of a population, it might be valuable on its own knowing that the population mean height is likely to fall between X and Y. If you have specific example of what the CI assesses, I can give you a more specific interpretation.
Additionally, I cover confidence intervals associated with many different types of hypothesis tests in my Hypothesis Testing ebook. You might consider looking in to that!
I hope that helps!
Hi Jim
I got a very wide 95% CI of the HR of height in the cox PH model from a very large sample. I already deleted the outliers defined as 1.5 IQR, but it doesn’t work. Do you know how to resolve it?
Hello, Jim!
I appreciate the thoughtful and thorough answer you provided. It really helped in crystallizing the topic for me.
If I may ask for a bit more of your time, as long as we are talking about CIs I have another question:
How would you go about constructing a CI for the difference of variances?
I am asking because while creating CIs for the difference of means or proportions is relatively straightforward, I couldn’t find any references for the difference of variances in any of my textbooks (or on the Web for that matter); I did find information regarding CIs for the ratio of variances, but it’s not the same thing.
Could you help me with that?
Thanks a lot!
Hello, Jim!
I want to start by thanking you for a great post and an overall great blog! Top notch material.
I have a doubt regarding the difference between confidence intervals for a point estimate and confidence intervals for a hypothesis test.
As I understand, if we are using CIs to test a hypothesis, then our point estimate would be whatever the null hypothesis is; conversely, if we are simply constructing a CI to go along with our point estimate, we’d use the point estimate derived from our sample. Am I correct so far?
The reason I am asking is that because while reading from various sources, I’ve never found a distinction between the two cases, and they seem very different to me.
Bottom line, what I am trying to ask is: assuming the null hypothesis is true, shouldn’t the CI be changed?
Thank you very much for your attention!
Hi Pedro,
There’s no difference in the math behind the scenes. The real difference is that when you create a confidence interval in conjunction with a hypothesis test, the software ensures that they’re using consistent methodology. For example, the significance level and confidence level will correspond correctly (i.e., alpha = 0.05 and confidence level = 0.95). Additionally, if you perform a two-tailed test, you will obtain a two-sided CI. On the other hand, if you perform a one-tailed test, you will obtain the appropriate upper or lower bound (i.e., one-sided CIs). The software also ensures any other methodological choices you make will match between the hypothesis test and CI, which ensures the results always agree.
You can perform them separately. However, if you don’t match all the methodology options, the results can differ.
As for your question about assuming the null is true. Keep in mind that hypothesis tests create sampling distributions that center on the null hypothesis value. That’s the assumption that the null is true. However, the sampling distributions for CIs center on the sample estimate. So, yes, CIs change that detail because they don’t assume the null is correct. But that’s always true whether you perform the hypothesis test or not.
Thanks for the great questions!
Hi Jim !!
Confidence interval has sample static as the most likely value ( value in the center) – and sample distribution assumes the null value to be the most likely value( value in the center). I am a little confused about this. Would be really kind of you if you could show both in the same graph and explain how both are related. How the the distance from the mean to a limit in case of Significance level and CI same?
Hi Jaser,
That’s a great question. I think part of your confusion is due to terminology.
The sampling distribution of the means centers on the sample mean. This sampling distribution uses your sample mean as its mean and the standard error of the mean as its standard deviation.
The sampling distribution of the test statistic (t) centers on the null hypothesis value (0). This distribution uses zero as its mean and also uses the SEM for its standard deviation.
They’re two different things and center on different points. But, they both incorporate the SEM, which is why they always agree! I do have section in this post about why that distance is always the same. Look for the section titled, “Why They Always Agree.”
I hope that helps!
Hi Jim, I’m the proud owner of 2 of your ebooks. There’s one topic though that keeps puzzling me:
If I would take 9 samples of size 15 in order to estimate the population mean, the se of the mean would be substantial larger than if I would take 1 sample of size 135 (divide pop sd by sqrt(15) or sqrt(135) ) whereas the E(x) (or mean of means) would be the same.
Can you please shine a little light on that.
Tx in advance
Gerard
Hi Gerard,
Thanks so much for supporting my ebooks. I really appreciate that!! 🙂
So, let’s flip that scenario around. If you know that a single large sample of 135 will produce more precise estimates of the population, why would you collect nine smaller samples? Knowing how statistics works, that’s not a good decision. If you did that in the real world, it would be because there was some practical reason that you could not collect one big example. Further, it would suggest that you had some reason for not being able to combine them later. For example, if you follow the same random sampling procedure on the same population and used all the same methodology and at the same general time, you might feel comfortable combining them together into one larger sample. So, if you couldn’t collect one larger example and you didn’t feel comfortable combining them together, it suggests that you have some reason for doubting that they all measure the same thing for the same population. Maybe you had differences in methodology? Or subjective measurements across different personnel? Or, maybe you collected the samples at different times and you’re worried that the population changed over time?
So, that’s the real world reason for why a researcher would not combine smaller samples into a larger one.
The mathematical reason for why one larger sample is better than a number of smaller samples is that the calculations for the small samples aren’t “aware” of the similar data in the other samples. The formula for the standard error of the mean (SEM) is below:
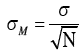
As you can see, the expected value for the population standard deviation is in the numerator (sigma). As the sample size increases, the numerator remains constant (plus or minus random error) because the expected value for the population parameter does not change. Conversely, the square root of the sample size is in the denominator. As the sample size increases, it produces a larger values in the denominator. So, if the expected value of the numerator is constant but the value of the denominator increases with a larger sample size, you expect the SEM to decrease. Smaller SEM’s indicate more precise estimates of the population parameter. For instance, the equations for confidence intervals use the SEM. Hence, for the same population, larger samples tend to produce smaller SEMS, and more precise estimates of the population parameter.
I hope that answers your question!
Hi Jim,
first of all: Thanks for your effort and your effective way of explaining!
You say that p-values and C.I.s always agree. I agree.
Why does Tim van der Zee claim the opposite?
I’m not enough into statistcs to figure this out.
http://www.timvanderzee.com/not-interpret-confidence-intervals/
Best regards
Georg
Hi Georg,
I think he is saying that they do agree–just that people often compare the wrong pair of CIs and p-values. I assume you’re referring to the section “What do overlapping intervals (not) mean?” And, he’s correct in what he says. In a 2-sample t-test, it’s not valid to compare the CI for each of the two group means to the test’s p-values because they have different purposes. Consequently, they won’t necessarily agree. However, that’s because you’re comparing results from two different tests/intervals.
On the one hand, you have the CIs for each group. On the other hand, you have the p-value for the difference between the two groups. Those are not the same thing and so it’s not surprising that they won’t agree necessarily.
However, if you compare the p-value of the difference between means to a CI of the difference between means, they will always agree. You have to compare apples to apples!
Hey Jim,
First of all, I love all your posts and you really do make people appreciate statistics by explaining it intuitively compared to theoretical approaches I’ve come across in university courses and other online resources. Please continue the fantastic work!!!
At the end, you mentioned how you prefer confidence intervals as they consider both “size and precision of the estimated effect”. I’m confused as to what exactly size and precision mean in this context. I’d appreciate an explanation with reference to specific numbers from the example above.
Second, do p-values lack both size and precision in determination of statistical significance?
Thanks,
Devansh
Hi Devansh,
Thanks for the nice comments. I really appreciate them!
I really need to write a post specifically about this issue.
Let’s first assume that we conduct our study and find that the mean cost is 330.6 and that we are testing whether that is different than 260. Further suppose that we perform the the hypothesis test and obtain a p-value that is statistically significant. We can reject the null and conclude that population mean does not equal 260. And we can see our sample estimate is 330.6. So, that’s what we learn using p-values and the sample estimate.
Confidence intervals add to that information. We know that if we were to perform the experiment again, we’d get different results. How different? Is the true population mean likely to be close to 330.6 or further away? CIs help us answer these questions. The 95% CI is [267 394]. The true population value is likely to be within this range. That range spans 127 dollars.
However, let’s suppose we perform the experiment again but this time use a much larger sample size and obtain a mean of 351 and again a significant p-value. However, thanks to the large sample size, we obtain a 95 CI of [340 362]. Now we know that the population value is likely to fall within this much tighter interval of only 22 dollars. This estimate is much more precise.
Sometimes you can obtain a significant p-value for a result that is too imprecise to be useful. For example, with first CI, it might be too wide to be useful for what we need to do with our results. Maybe we’re helping people make budgets and that is too wide to allow for practical planning. However, the more precise estimate of the second study allows for better budgetary planning! That determination how much precision is required must be made using subject-area knowledge and focusing on the practical usage of the results. P-values don’t indicate the precision of the estimates in this manner!
I hope this helps clarify this precision issue!