Histograms are graphs that display the distribution of your continuous data. They are fantastic exploratory tools because they reveal properties about your sample data in ways that summary statistics cannot. For instance, while the mean and standard deviation can numerically summarize your data, histograms bring your sample data to life.
In this blog post, I’ll show you how histograms reveal the shape of the distribution, its central tendency, and the spread of values in your sample data. You’ll also learn how to identify outliers, how histograms relate to probability distribution functions, and why you might need to use hypothesis tests with them.
Histograms, Central Tendency, and Variability
Use histograms when you have continuous measurements and want to understand the distribution of values and look for outliers. These graphs take your continuous measurements and place them into ranges of values known as bins. Each bin has a bar that represents the count or percentage of observations that fall within that bin. Histograms are similar to stem and leaf plots.
Download the CSV data file to make most of the histograms in this blog post: Histograms.
In the field of statistics, we often use summary statistics to describe an entire dataset. These statistics use a single number to quantify a characteristic of the sample. For example, a measure of central tendency is a single value that represents the center point or typical value of a dataset, such as the mean. A measure of variability is another type of summary statistic that describes how spread out the values are in your dataset. The standard deviation is a conventional measure of dispersion.
These summary statistics are crucial. How often have you heard that the mean of a group is a particular value? It provides meaningful information. However, these measures are simplifications of the dataset. Graphing the data brings it to life. Generally, I find that using graphs in conjunction with statistics provides the best of both worlds!
Let’s see this in action.
Related posts: Measures of Central Tendency, What is the Mean?, Measures of Variability and Using the Standard Deviation.
Histograms and the Central Tendency
Use histograms to understand the center of the data. In the histogram below, you can see that it is a unimodal distribution because it has only one peak near 50. Most values in the dataset will be close to 50, and values further away are rarer. The distribution is roughly symmetric and the values fall between approximately 40 and 64.

A difference in means shifts the distributions horizontally along the X-axis (unless the histogram is rotated). In the histograms below, one group has a mean of 50 while the other has a mean of 65.

Additionally, histograms help you grasp the degree of overlap between groups. In the above histograms, there’s a relatively small amount of overlap.
Learn more about Unimodal Distributions: Definition & Examples.
Histograms and Variability
Suppose you hear that two groups have the same mean of 50. It sounds like they’re practically equivalent. However, after you graph the data, the differences become apparent, as shown below.

The histograms center on the same value of 50, but the spread of values is notably different. The values for group A mostly fall between 40 – 60 while for group B that range is 20 – 90. The mean does not tell the entire story! At a glance, the difference is evident in the histograms.
In short, histograms show you which values are more and less common along with their dispersion. You can’t gain this understanding from the raw list of values. Summary statistics, such as the mean and standard deviation, will get you partway there. But histograms make the data pop!
Histograms and Skewed Distributions
Histograms are an excellent tool for identifying the shape of your distribution. So far, we’ve been looking at symmetric distributions, such as the normal distribution. However, not all distributions are symmetrical. You might have nonnormal data that are skewed.
The shape of the distribution is a fundamental characteristic of your sample that can determine which measure of central tendency best reflects the center of your data. Relatedly, the shape also impacts your choice between using a parametric or nonparametric hypothesis test. In this manner, histograms are informative about the summary statistics and hypothesis tests that are appropriate for your data.
For skewed distributions, the direction of the skew indicates which way the longer tail extends.
For right-skewed distributions, the long tail extends to the right while most values cluster on the left, as shown below. These are real data from a study I conducted.

Conversely, for left-skewed distributions, the long tail extends to the left while most values cluster on the right.

Related posts: The Normal Distribution in Statistics and Parametric vs. Nonparametric Hypothesis Tests
Using Histograms to Identify Outliers
Histograms are a handy way to identify outliers. In an instant, you’ll see if there are any unusual values. If you identify potential outliers, investigate them. Are these data entry errors or do they represent observations that occurred under unusual conditions? Or, perhaps they are legitimate observations that accurately describe the variability in the study area.

In a histogram, outliers appear as an isolated bar.
Related posts: 5 Ways to Find Outliers and Guidelines for Removing Outliers
Identifying Multimodal Distributions with Histograms
All the previous histograms display unimodal distributions because they have only one peak. A multimodal distribution has more than one peak. It’s easy to miss multimodal distributions when you focus on summary statistics, such as the mean and standard deviations. Consequently, histograms are the best method for detecting multimodal distributions.
Imagine your dataset has the properties shown below.

That looks relatively straightforward, but when you graph it, you see the histogram below.

That bimodal distribution is not quite what you were expecting! This histogram illustrates why you should always graph your data rather than just calculating summary statistics!
Related post: Bimodal Distributions: Definition, Examples & Analysis
Using Histograms to Identify Subpopulations
Sometimes these multimodal distributions reflect the actual distribution of the phenomenon that you’re studying. In other words, there are genuinely different peak values in the distribution of one population. However, in other cases, multimodal distributions indicate that you’re combining subpopulations that have different characteristics. Histograms can help confirm the presence of these subpopulations and illustrate how they’re different from each other.
Suppose we’re studying the heights of American citizens. They have a mean height of 168 centimeters with a standard deviation of 9.8 CM. The histogram is below. There appears to be an unusually broad peak in the center—it’s not quite bimodal.
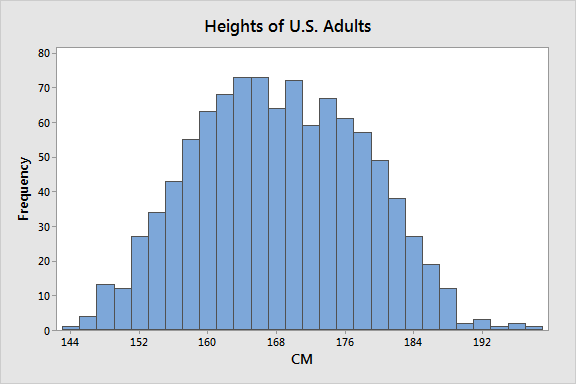
When we divide the sample by gender, the reason for it becomes clear.

Notice how two narrower distributions have replaced the single broad distribution? The histograms help us learn that gender is an essential categorical variable in studies that involve height. The graphs show that the mean provides more precise estimates when we assess heights by gender. In fact, the mean for the entire population does not equal the mean for either subpopulation. It’s misleading!
Related post: Dot Plots: Using, Examples, and Interpreting
Using Histograms to Assess the Fit of a Probability Distribution Function
Analysts can overlay a fitted line for a probability distribution function on their histogram. Here’s a quick distinction between the two:
- Histogram: Displays the distribution of values in the sample.
- Fitted distribution line: Displays the probability distribution function for a particular distribution (e.g., normal, Weibull, etc.) that best fits your data.
A histogram graphs your sample data. On the other hand, a fitted distribution line attempts to find the probability distribution function for a population that has the maximum likelihood of producing the distribution that exists in your sample.
While you can use histograms to evaluate how well the distribution curve fits your sample, I do NOT recommend it! If you insist on using a histogram, assess how closely the bars follow the shape of the fitted line. In the graph below, the fitted line for the normal distribution appears to follow the histogram bars adequately. The legend displays the estimated parameter values of the fitted distribution.

Instead of using histograms to determine how well a distribution fits your data, I recommend using a combination of distribution tests and probability plots. Probability plots are special graphs that are specifically designed to display how well probability distribution functions fit samples. To learn more about these other approaches, read my posts about Identifying the Distribution of your Data and Histograms vs. Probability Plots.
Related post: Understanding Probability Distributions
Using Histograms to Compare Distributions between Groups
To compare distributions between groups using histograms, you’ll need both a continuous variable and a categorical grouping variable. There are two common ways to display groups in histograms. You can either overlay the groups or graph them in different panels, as shown below.


It can be easier to compare distributions when they’re overlaid, but sometimes they get messy. Histograms in separate panels display each distribution more clearly, but the comparisons and degree of overlap aren’t quite as clear. In the examples above, the paneled distributions are clearly more legible. However, overlaid histograms can work nicely in other cases, as you’ve seen in this blog post. Experiment to find the best approach for your data!
While I think histograms are the best graph for understanding the distribution of values for a single group, they can get muddled with multiple groups. Histograms are usually pretty good for displaying two groups, and up to four groups if you display them in separate panels. If your primary goal is to compare distributions and your histograms are challenging to interpret, consider using boxplots or individual plots. In my opinion, those other plots are better for comparing distributions when you have more groups. But they don’t provide quite as much detail for each distribution as histograms.
Again, experiment and determine which graph works best for your data and goals!
Related post: Box Plot Explained with Examples
Histograms and Sample Size
As fantastic as histograms are for exploring your data, be aware that sample size is a significant consideration when you need the shape of the histogram to resemble the population distribution. Typically, I recommend that you have a sample size of at least 50 per group for histograms. With fewer than 50 observations, you have too little data to represent the population distribution accurately.
Both histograms below use samples drawn from a population that has a mean of 100 and a standard deviation of 15. These characteristics describes the distribution of IQ scores. However, one histogram uses a sample size of 20 while the other uses a sample size of 100. Notice that I’m using percent on the Y-axis to compare histogram bars between different sample sizes.

That’s a pretty huge difference! It takes a surprisingly large sample size to get a good representation of an entire distribution. When your sample size is less than 20, consider using an individual value plot.
Using Hypothesis Tests in Conjunction with Histograms
As you’ve seen in this post, histograms can illustrate the distribution of groups as well as differences between groups. However, if you want to use your sample data to draw conclusions about populations, you’ll need to use hypothesis tests. Additionally, be sure that you use a sampling method, such as random sampling, to obtain a sample that reflects the population.
Related posts: Difference between Descriptive and Inferential Statistics and Populations, Parameters and Samples in Inferential Statistics
Differences between groups that are visible on histograms can be quirks caused by random sampling error rather than representing real differences between populations. On histograms, random error can manifest itself as differences between central tendency and variability. Additionally, arbitrary graph factors such as the scale of the Y-axis and different bin sizes can overstate the differences.
Hypothesis tests play a critical role in separating the signal (real differences in the population) from the noise (random sampling error). This protective function helps prevent you from mistaking random error for a real effect. If the appropriate hypothesis test is not statistically significant, your sample provides insufficient evidence for concluding that the pattern on your graph represents a real effect at the population level. In other words, you might be looking at noise in the sample.
Hypothesis Tests for Histograms
Use the following hypothesis tests in conjunction with histograms when you are comparing groups:
2-sample t-test: Assess the equality of two group means.
ANOVA: Test the equality of three or more group means.
Mann-Whitney: Assess the equality of two group medians.
Kruskal-Wallis and Mood’s Median: Test the equality of three or more group medians.
Test of Equal Variances: Assess the equality of group variances or standard deviations.
Histograms are a great way to investigate your data. However, when you need to draw inferences about an entire population, be sure to use a representative sampling method and the proper hypothesis test.
Related post: Median: Definition and Uses

I am in college and learning about Histograms. Can they be used for any level of measurement, Nominal, Ordinal or Interval-Ratio?
Hi Mary,
You should use histograms only for interval and ratio scale data. Basically, numeric data.
Nominal and Ordinal data are discrete. Use bar charts to display those data types.
Histograms and bar charts both use bars, but the bars on bar charts are separated by spaces to represent the discrete values.
Histograms use a numeric X-axis (horizontal). Technically, it’s possible to use a histogram to display ordinal data if you code the ordinal values as numbers. However, best practice is to use a bar chart to get those separate bars.
Nominal data don’t have numeric values and, therefore, cannot be graphed on a histogram.
I hope that helps!
You might also consider John Tukey’s stem-and-leaf plots. They are very informative for continuous data.
It does! That’s a really clear distinction. Thank you 🙂
Hi Jim,
This may be a stupid question but I’ve seen many sources saying that frequency distributions of discrete data can be visualized using a bar chart or a histogram, i.e. histograms can be used for both discrete data and continuous data, as long as discrete data has gaps between bars.
Is this accurate? And if so, what differentiates a discrete data bar chart and histogram? Is is simply that the y-axis in a histogram measures the frequency?
Hi Catherine,
Here’s the technical details for both. Histograms do not have spaces between the bars and are meant for use with continuous data. Bar charts do have spaces between bars and are meant for discrete data. For discrete probability distributions, you’d use a bar chart (the one with spaces). Don’t use a histogram for discrete data.
The continuous vs discrete and no spaces/space are really the distinguishing features. Both charts can display frequencies on the y-axis.
I hope that helps!
Hi Jim,
this was very helpful. I have a question though. from a histogram, how can I determine if the information displayed comes from one population?
Ernest.
Hi Ernst,
There’s no way to determine from a histogram whether it’s from a sample or population. At least not be the histogram itself. Hopefully, whoever created the histogram explains the data. The write up should explain whether it’s a sample or an entire population. If it’s a sample, it should explain how it was drawn. That’s always good practice. However, you will almost never see a histogram for an entire population because it’s usually impossible to measure an entire population. At least that’s from the perspective of inferential statistics. If you’re just using a histogram to describe a group, then the write up should explain that. For example, this histogram shows the distribution of scores from Mrs. Smith’s math class. Read my post about inferential vs. descriptive statistics for more information about that distinction.
So look at the write up and/or information on the graph itself to see where the data are from.
I hope that helps!
Hi, is there any way to get individual measurements from size sample, min, max, SD, SE and mean?
Thank you so much for this informative and knowledgeable article.
I have questions please:
1. In the section “Histograms and Variability” In the importance of the Histogram, you mentioned that in some cases, we have the same mean (Average) of 2 datasets but the histogram looks different.
What this tells us? what if the histogram is difference? is that mean the quality of the data is low in the 1st dataset?
2. What does Standard Derivation tell us , I mean if we have 2 datasets with below Standard Derivation :SD of Dataset1 = 1
SD of Dataset2 = 100
What this indicates? is that mean the 2nd DS is low quality ? or we tell us that there is extra step we should do before we start processing those data?
I am still have confusing on the important of Standard Derivation and the histogram when we deals with different types of Datasets.
Thank you so much in advance and have happy new year 🙂 .
Hi Ebtihal,
There’s no general rule for what it means exactly. It’s not necessarily lower quality data. You, as the analyst, need to understand the data and the context in which it was collected.
For variability, histograms help you understand how spread out the values are but they don’t tell you why they are spread out. Differences in spread might be simply the natural properties of the parent populations rather than a difference in data quality. Two histograms with different spreads might accurately reflect the subject area using high quality data. On the other hand, it’s also possible that a less precise measurement system might produce more variable data in one population. In that case, it would be lower quality data. However, you can’t tell by simply looking at the histogram. You have to understand the subject area, what the data represent, and how the data are collected.
Variability, of which standard deviations are one measure, tells you how spread out the data points are. More variable data have wider ranges and more diverse values. Less variable data have tighter distributions and less diverse values. There are numerous potential reasons for why different populations or subpopulations can have different variability. Graphs can help you understand the properties of your data but you’ll need to investigate to understand why the data have these properties.
I hope this helps!
Hi, thanks for the nice post. I am wondering if there are any exercises with the CSV file that you mention in this article.
HI JIm, from last 2 years, i am working as a computer vision engineer, now i thought to be skilled myself into datascience field, i have read in your comment, you have published a e-book on intuitive statistics,can u please share link to it, will be a great help to us.
Hi Vikrant,
Yes, I’ve just recently published an ebook. Look in the right-hand column of any page of my website and you’ll see it there. I also published a blog post about my ebook. I hope you find it useful!
Thanks for writing! And welcome to data science!
Glad to hear this!
Looking forward eagerly for the upcoming compiled resources. Thank you!!!
Thanks, Tsegaye! The ebook will be more than just a compilation. The majority of it is new content!
Woow!
Currently I am working on some project which really needs statistics knowledge. My ultimate objective is to to develop linear regression model between two concrete compressive strength datas and investigating/comparing the reliability of this two regression equations. I hope hypothesis testing and such methods will help me a lot. This is really helpful. But it will be much better if you provide us all this notes in one compiled book.
Hi Tsegaye,
You’re in luck, and this is great timing! In approximately 2 weeks (March 2019), I’ll be releasing my first ebook, which will be all about regression analysis. Be on the lookout for it!
Thanks for writing!
Thank you so much for all your posts Jim – they’ve made me rediscover my love for statistics!
I used to love stats, but I always performed badly in my university exams as we were taught very complex theory, but not anything about how to think about it intuitively. Have you ever considered putting together all the posts into a book (or e-book)? I think that would be super useful! I’m currently downloading all the posts separately as pdf files and highlighting the most important parts. But having all the information in one place would make it so much more convenient.
Keep up the good work!
Hi Kara,
Your kind comments really made my day! Thank you! I love statistics and I think there is so much more to them than most people realize. It’s the science of learning from data, after all. That’s pretty cool! Unfortunately, I think you’re right in that often the way the subject is taught is overly complex and it’s difficult to discover the exciting parts of statistics.
As a matter of fact, in just about two weeks, I’m releasing my first full-length ebook! It’s about regression analysis and it goes far beyond what I can do in blog posts, but I use the same plain language, intuitive, practical approach that I use in my blog posts. If that ebook is well received, I’ll do more for other statistical areas–such as an intro type book.
thanks so much……… this was really helpfull
Jim,
I was working for a client who took histograms of particle size distribution measurements from process samples. The instrument actually took hundreds of individual particle size measurements of each sample extremely quickly and reported a histogram of a composite of the measurements for each batch sample. It was interesting that the histograms from all the batch samples had no extreme or near extreme particle sizes. But the probability distribution inferred from the histograms of course had extreme values.
The samples represent product batches, which the client believed had extreme particle sizes in his product because of finding a prov dist. function for the histogram, and set product specifications accordingly. Also, it was responsible for misunderstanding how the product functioned.
Histograms in my experience mislead too often. And probability distribution functions inferred from sample data (i.e., histograms) do not necessarily represent the product.
Regards,
Stan Alekman
Stanley, those are definitely worthwhile lessons. Thanks for sharing!
One thing I do mention in this post is that I wouldn’t normally use histograms to pick a probability distribution function. I think there are better tools. In a post about identifying the distribution of data, the decision came down to two candidates. The biggest difference between them is how they model the tails. Does the function allow for more extreme values or not? Which reminds me of your client. For the example data, I chose the distribution that allows for more extreme values based on subject-area knowledge. Of course, as your client’s story shows, that type of decision varies by subject area. I’m also a strong believer in using subject-area expertise to guide the analyses.
Hi Jim,
Histograms often mislead, sometimes egregiously. I prefer Shewhart plots.
When there are 20, preferably 30 or more values sampled sequentially by a random sampling process, it is helpful to plot a Shewhart individuals chart to assess homogeneity of the data. If the plot demonstrates statistical control by application of the first three rules, the sample may be considered homogeneous, also representative of the source. If the source is a fixed population, the population may be considered homogeneous. The statistics of the sample are then reasonably representative of the source.
Regards,
Stan Alekman
Hi Stan,
It’s great to hear from you again!
First, for the benefit of others, Shewhart charts are also known as control charts and they are commonly used to determine whether manufacturing or business processes are stable. I think they are wonderful charts. In fact, I’ve written a blog post suggesting that analysts should use control charts with hypothesis tests even outside the field of quality improvement. I think you can make the same argument that you should use them before creating a histogram. I share your enthusiasm for these charts!
That all said, histograms and control charts have different purposes. I think histograms are great tool for understanding the distribution of your data. Control charts are a great tool for ensuring that your sampling from a stable population. I wouldn’t use one of those charts for the purpose of the other chart.
Also, I think histograms are fairly reliable assuming the analyst isn’t monkeying with the bins or what not. Usually they’ll paint a good picture of your data’s distribution when let the software choose the bin sizes. The big downside I find for histograms is that they require a fairly large sample size to accurately represent a distribution. That’s not really the histogram’s fault, but rather it reflects the amount of data required to accurately portray a distribution. In the sample size section in this post, I show how a sample size of 20 produces a histogram that doesn’t resemble the underlying population.
Cheers!