What are Degrees of Freedom?
The degrees of freedom (DF) in statistics indicate the number of independent values that can vary in an analysis without breaking any constraints. It is an essential idea that appears in many contexts throughout statistics including hypothesis tests, probability distributions, and linear regression. Learn how this fundamental concept affects the power and precision of your analysis!
In this post, I bring this concept to life in an intuitive manner. You’ll learn the degrees of freedom definition and know how to find degrees of freedom for various analyses, such as linear regression, t-tests, and chi-square. I’ll start by defining degrees of freedom and providing the formula. However, I’ll quickly move on to practical examples in the context of various statistical analyses because they make this concept easier to understand.
Degrees of Freedom Definition
What are degrees of freedom in statistics? Degrees of freedom are the number of independent values that a statistical analysis can estimate. You can also think of it as the number of values that are free to vary as you estimate parameters. I know, it’s starting to sound a bit murky!
DF encompasses the notion that the amount of independent information you have limits the number of parameters that you can estimate. Typically, the degrees of freedom equals your sample size minus the number of parameters you need to calculate during an analysis. It is usually a positive whole number.
Degrees of freedom is a combination of how much data you have and how many parameters you need to estimate. It indicates how much independent information goes into a parameter estimate. In this vein, it’s easy to see that you want a lot of information to go into parameter estimates to obtain more precise estimates and more powerful hypothesis tests. So, you want many DF!
Independent Information and Constraints on Values
The degrees of freedom definitions talk about independent information. You might think this refers to the sample size, but it’s a little more complicated than that. To understand why, we need to talk about the freedom to vary. The best way to illustrate this concept is with an example.
Suppose we collect the random sample of observations shown below. Now, imagine we know the mean, but we don’t know the value of an observation—the X in the table below.

The mean is 6.9, and it is based on 10 values. So, we know that the values must sum to 69 based on the equation for the mean.
Using simple algebra (64 + X = 69), we know that X must equal 5.
Related post: What is the Mean in Statistics?
How to Find the Degrees of Freedom in Statistics
As you can see, that last number has no freedom to vary. It is not an independent piece of information because it cannot be any other value. Estimating the parameter, the mean in this case, imposes a constraint on the freedom to vary. The last value and the mean are entirely dependent on each other. Consequently, after estimating the mean, we have only 9 independent pieces of information, even though our sample size is 10.
That’s the basic idea for DF in statistics. In a general sense, DF are the number of observations in a sample that are free to vary while estimating statistical parameters. You can also think of it as the amount of independent data that you can use to estimate a parameter.
Degrees of Freedom Formula
The degrees of freedom formula is straightforward. Calculating the degrees of freedom is often the sample size minus the number of parameters you’re estimating:
DF = N – P
Where:
- N = sample size
- P = the number of parameters or relationships
For example, the degrees of freedom formula for a 1-sample t test equals N – 1 because you’re estimating one parameter, the mean. To calculate degrees of freedom for a 2-sample t-test, use N – 2 because there are now two parameters to estimate.
The degrees of freedom formula for a table in a chi-square test is (r-1) (c-1), where r = the number of rows and c = the number of columns.
DF and Probability Distributions
Degrees of freedom also define the probability distributions for the test statistics of various hypothesis tests. For example, hypothesis tests use the t-distribution, F-distribution, and the chi-square distribution to determine statistical significance. Each of these probability distributions is a family of distributions where the DF define the shape. Hypothesis tests use these distributions to calculate p-values. So, the DF directly link to p-values through these distributions!
Next, let’s look at how these distributions work for several hypothesis tests.
Related posts: Understanding Probability Distributions and A Graphical Look at Significance Levels (Alpha) and P values
Degrees of Freedom for t Tests
T tests are hypothesis tests for the mean and use the t-distribution to determine statistical significance.
A 1-sample t test determines whether the difference between the sample mean and the null hypothesis value is statistically significant. Let’s go back to our example of the mean above. We know that when you have a sample and estimate the mean, you have n – 1 degrees of freedom, where n is the sample size. Consequently, for a 1-sample t test, use n – 1 to calculate degrees of freedom.
The DF define the shape of the t-distribution that your t-test uses to calculate the p-value. The graph below shows the t-distribution for several different degrees of freedom. Because the degrees of freedom are so closely related to sample size, you can see the effect of sample size. As the DF decreases, the t-distribution has thicker tails. This property allows for the greater uncertainty associated with small sample sizes.
The degrees of freedom chart below displays t-distributions.

To dig into t-tests, read my post about How t-Tests Work. I show how the different t-tests calculate t-values and use t-distributions to calculate p-values.
The F-test in ANOVA also tests group means. It uses the F-distribution, which is defined by the DF. However, you calculate degrees of freedom in ANOVA differently because you need to find the numerator and denominator DF. For more information, read my post about How F-tests Work in ANOVA.
Degrees of Freedom Table
You’ll often find degrees of freedom in statistical tables along with their critical values. Statisticians use the DF in these tables to determine whether the test statistic for their hypothesis test falls in the critical region, indicating statistical significance.
For example, in a t-table, you’ll find the degrees of freedom in the first column of the table. You must know the degrees of freedom to find the corresponding critical values. In the example below, the t-table indicates that for a two-tailed t-test with 20 DF and an alpha of 0.05, the critical values are -2.086 and +2.086.

Other hypothesis tests, such as the chi-square, F-tests, and z-tests, have their own tables where you can find degrees of freedom and the corresponding critical values.
Related posts: How to Interpret P-values Correctly and T Distribution Table
How to Find Degrees of Freedom for Tables in Chi-Square Tests
The chi-square test of independence determines whether there is a statistically significant relationship between categorical variables in a table. Just like other hypothesis tests, this test incorporates DF. To find the chi-square DF for a table with r rows and c columns, use this formula to calculate degrees of freedom: (r-1) (c-1).
However, we can create tables to understand how to find degrees of freedom more intuitively. The DF for a chi-square test of independence is the number of cells in the table that can vary before you can calculate all the other cells. In a chi-square table, the cells represent the observed frequency for each combination of categorical variables. The constraints are the totals in the margins.
Chi-Square 2 X 2 Table
For example, to find the degrees of freedom in a 2 X 2 table, after you enter one value in the table, you can calculate all the remaining cells.

In the table above, I entered the bold 15, and then I can calculate the remaining three values in parentheses. Therefore, this table has 1 DF.
Chi-Square 3 X 2 Table
Now, let’s try finding degrees of freedom for 3 X 2 table. The table below illustrates the example that I use in my post about the chi-square test of independence. In that post, I determine whether there is a statistically significant relationship between uniform color and deaths on the original Star Trek TV series.

In the table, one categorical variable is shirt color, which can be blue, gold, or red. The other categorical variable is status, which can be dead or alive. After I entered the two bolded values, I can calculate all the remaining cells. Consequently, this table has 2 DF.
Read my post, Chi-Square Test of Independence and an Example, to see how this test works and how to interpret the results using the Star Trek example.
Like the t-distribution, the chi-square distribution is a family of distributions where the DF define the shape. Chi-square tests use this distribution to calculate p-values. The degrees of freedom chart below displays several chi-square distributions.

Related post: Chi-Square Table
Linear Regression Degrees of Freedom
Calculating degrees of freedom in linear regression is a bit more complicated, and I’ll keep it on the simple side. In a linear regression model, each term is an estimated parameter that uses one degree of freedom. In the regression output below, you can see how each linear regression term requires a DF. There are n = 29 observations, and the two independent variables use a total of two DF.
The degrees of freedom formula for total DF = n – 1, which is 29 – 1 = 28 in our example. The degrees of freedom formula for Error DF is: n – P – 1. In our example that is 29 – 2 – 1 = 26. P is the number of coefficients not counting the constant. The output displays the remaining 26 degrees of freedom in Error.

In linear regression, the error DF are the independent pieces of information that are available for estimating your coefficients. For precise coefficient estimates and powerful hypothesis tests in regression, you must have many error degrees of freedom, which equates to having many observations for each model term.
As you add terms to the model, the error degrees of freedom decreases. You have fewer pieces of information available to estimate the coefficients. This situation reduces the precision of the estimates and the power of the tests. When you have too few remaining DF, you can’t trust the regression results. If you use all your linear regression degrees of freedom, the procedure can’t calculate the p-values.
For more information about the problems that occur when you use too many DF and how many observations you need, read my blog post about overfitting your model.
Even though the degrees of freedom definition might seem murky, they are essential to any statistical analysis! In a nutshell, DF define the amount of information you have relative to the number of properties that you want to estimate. If you don’t have enough data for what you want to do, you’ll have imprecise estimates and low statistical power.
If you’re learning about hypothesis testing and like the approach I use in my blog, check out my Hypothesis Testing book! You can find it at Amazon and other retailers.

References
Walker, H. W. Degrees of Freedom. Journal of Educational Psychology. 31(4) (1940) 253-269.
Pandy, S., and Bright, C. L., Social Work Research Vol 32, number 2, June 2008.
Share this:

Reader Interactions
Comments
Comments and Questions

I define DF thus: a degree of freedom is an independent parameter in the formal description of the state of a system. The set of all states of a system is known as the system’s phase space, and the degrees of freedom of the system are the dimensions of this phase space
great post!
Hi there!
If I run a t test between 2 linear regressions, ie. 2 slopes, do I need to compare against a t crit of n – 4 degrees of freedom?
Thanks!
Hi Lince,
I’d recommend using an interaction term to do that. That uses a single DF to include that term. For more information, read my post about comparing regression slopes.
Okay, cool! Thanks for creating all these helpful resources.
I may be getting turned around, but the regression output seems to suggest 29 observations, not 28. Wouldn’t 28 observations mean a total df of 27 and residual df of 25, as opposed to 28 and 26?
Hi Seth, you’re right! Thanks for catching the typo! I’ve updated and expanded the calculations in that section a bit to make it clearer.
Hi! I am new to statistics and the question I have to answer is “What are the degrees of freedom for the following? Means and difference in means test. Am i correct with the formulas?
– Means – df = n-1
– difference in means tests – numbers of pairs minus 1
Hi Jim,
Excellent explanation of DF! Two questions. First, in the 2X2 table for chi-square, you say if you enter one value then you can estimate all the others — but you would have to have the marginal values (row totals and column totals) known, correct? You might consider editing that section to make that clearer.
Second, are the Star Trek numbers real data?
Thanks! I do mention the constraints being in the margins in the last sentence of the paragraph just before the Chi-Square 2X2 Table heading.
The Star Trek numbers are as real as they can be for a TV show! I didn’t collect them, but the deaths are based on onscreen fatalities in the episodes. And there are apparently some official numbers for the crew totals.
Hi Jim,
I am doing a 2 x 2 x 4 mixed ANCOVA and I keep getting a residual degrees of freedom value (141) that is greater than my sample size (52) for the 4-level IV and its interactions. Other variables show what I think is the correct value for df2 which is 47. Is it possible that the higher value is correct and I am missing something essential?
why does normal distribution don’t have degrees of freedom while estimating population mean.
Hi Hrithik,
If you’re using a sample to estimate the parameters (mean and standard deviation) of a normally distributed population, then those parameter estimates, including the mean, will indeed incorporate the degrees of freedom.
Hi Jim,
I keep getting zero df for my residual error. What does this mean?
Thanks,
Kerry
Hi Kerry,
That means you’re estimating as many parameters as you have observations. There are no observations left over for the error degrees of freedom. That’s not good! You’re overfitting your model. And your statistical software won’t be able to calculate p-values and CIs. You should remove some terms from your model.
Respected Jim,
If you are working with a sample and want to use it to estimate the population mean, do you need to divide by N-1? if not, why?
Thanks in advance.
Yes. I describe the reasons within this post. Basically, you’re estimating one parameter, so you need to use a DF for that. I show an example of estimating the mean in this post. Read that section carefully!
Hi Jim, thanks for sharing your knowledge. Can you please explain how to find if a dg of freedom is high or low? I mean let’s say i have a t-test and I find out my degree of freedom is 36. How should I compare it to realize if it is big?
Hi Kian,
Typically, analysts won’t assess whether their DF is low or high. The problem is that you can always say that higher is better! And it varies by analysis and by what size effect is important to detect. Chi-squared tests often have very low DF. Your 36 DF might be large for some of those cases but too small in others. It depends on all the details. But, fear not! There is a method by which analysts can assess all of that.
Instead, analysts will assess the power of their study and determine the sample size in advance. While they might not be thinking about it in terms of DF, they’re effectively ensuring that they have enough DF. If your sample size is too small, you won’t be able to detect effects. You effectively have too low of a DF. However, if the test can detect important effects with a reasonable power, then your DF are adequate. If your test can detect smaller effects than necessary with a high power, then your DF are high.
Click the link above to read my post about power analysis. That’ll help you understand how analysts think about that type of question.
I hope that helps!
So, conduct a power analysis before collecting data and that will help ensure that you have a sufficient number of DF!
Hi there,
If I draw two samples from ‘one population’, will my DF be (n1 + n2 – 2) or it will be (N – 1). Where n1 and n2 are sample sizes and N is (n1 + n2)?
But why? If variance is a measure of mean difference from the mean, why do you need a different denominator depending whether you have the whole population or not?
Hi Chris,
It all comes down to whether you’re estimating a population parameter or not. If you’re describing a specific group, then it’s not an estimation. It is what it is. However, when you’re estimating parameters, you need to worry about how many independent pieces of information you’re using to estimate that parameter. How many values are free to vary. And, as I show in this post, you have one less than your sample size for the mean.
how we can make dummy variable from multinomial variable?
HI Gemechu,
I discuss this in detail in my book about regression analysis.
In a nutshell, you need to create N-1 new dummy variables, where N is the number of levels in your categorical variable. Each dummy variable has values of 1 or 0. An observation has a value of 1 when that observation has the characteristic captured by that dummy variable. The value is zero when that characteristic is not present. There’s a reason why you leave one level out, and it’ll affect your results.
Again, for more details, I recommend my book where I cover this in depth and show examples!
Thanks so much for this surgical explanation. Also I have One question. why we use variance when compare means of the groups in ANOVA by using F- distribution?
Hi Gemechu,
Ah, you’re in luck! I’ve written a post that explains why we use variances to test means! Read the following: How F-tests Work in ANOVA. If you have more questions after reading that post, please don’t hesitate to post questions there!
Dear Dr. Jim,
Thanks for explaining the most common term in a very easy manner.
P. C. Srivastava
why we use n-1 for calculate the variance of sample and not when calculate the variance of population
Hi Gemechu,
Generally speaking, you use a degree of freedom for each parameter you’re estimating. When you’re using a sample to estimate a characteristic of a population (i.e., population parameter), you use a degree of freedom. Hence, n-1 for sample variance. However, if you measurements for the entire population or group that you’re interested in, you’re not estimating a parameter. You know the exact variance for that group/population. Because there is no estimation, you use n.
Thank you for this.
As you mentioned, the DF is N-1. I have a small query when we are randomly selecting 10 numbers from a set of 100 values, then DF is 100-10?
Hi, jim , hope u well there , jim plz help me out stiil didn’t get how to calculate df ??????? If we have 3 treatments each have 5 different values , so how ro calculate df ????
A very nice post!!!
May I share with you the following reflection (sorry, it’s a bit long!)? I hope I’m not out of topic…
Very often, I heard myself ask a question like this one:
“When we speak in terms of descriptive statistics, we calculate the variance by inserting within its formula a division for n (number of available observations); on the other side, when we are caught up with the inferential statistics, sample variance is calculated by a division for n-1;…but… Why? And why the ‘degrees of freedom’ are so important in this case?”
I searched an answer that was as simple as possible, with no recourse to mathematical instruments. And recently, also thanks to this post (I hope I understand it properly!), I “built” this kind of explanation:
– When we are dealing with inferences, we are interested in ‘bringing us as much information as possible’, so we are interested in working with data that are independent between them; within the sample variance we have a constraint on the data because we need to include within its formula an estimate of the mean, so the number of data that are independent for us is the number of starting data – 1 (represented by the imposed constraint);
– In descriptive statistics, the problem does not arise, since what is done with variance is simply getting information on the variability of the studied population, given by the average of the square deviations from the mean.
You often can hear/read this sentence: “Sampling variance estimator is biased! But if we do a division for n-1 instead of n (with n –> number of observations), however, we find the desired unbiased estimator!”.
Ok.
But why does sampling variance, if calculated in a ‘classical’ manner (with the division by n), is biased? That is, can we expect to get a biased estimator whenever we have a problem of “degrees of freedom”? That is, there is a direct link between the fact that a statistic is biased and the number of degrees of freedom within it? Is it all just a mere problem of calculation, of the definition of the formula of variance, or is there something a little deeper?
The concept of «degrees of freedom» and of «a statistic that is not biased» are in my opinion closely linked together, and therefore, starting with the fact that we have more or less degrees of freedom we can expect a more or less large bias.
That is:
– when I make an estimate on a population mean with the sample mean I can make a random mistake due to the fluctuations of my sample; this error is obviously canceled by applying an average to my sample means that are calculated on different samples;
– when I estimate the population variance with the sample variance (calculated in this case by dividing for n) I can make a mistake due to the random nature of the problem, but my errors are not simply eliminated by applying an average to my sample variance values calculated on different samples. In fact, inside the sample variance I also have a further constraint (the use of a sample mean) which is a sort of additional error, and which needs an “ad hoc” correction (the n-1 division); to have that the average of my estimates ‘works well’ (i.e. it produces the true value of the parameter of the population, i.e. to have an unbiased estimator), it must be applied to values of variance samples obtained from actually independent data, in other terms to → the number of data that I have collected minus the number of constraints ( in this case –> 1, represented by the sample mean).
In your opinion, is the previous explanation correct/effective/interesting or not?
How could I correct/improve my answer?
Thank you very much for all your patience!
Marco
It depends on what you are calculating , as mentioned it is for regression.
The df(Regression) is one less than the number of parameters being estimated. There are k predictor variables and so there are k parameters for the coefficients on those variables. There is always one additional parameter for the constant so there are k+1 parameters. But the df is one less than the number of parameters, so there are k+1 – 1 = k degrees of freedom. That is, the df(Regression) = # of predictor variables.
The df(Residual) is the sample size minus the number of parameters being estimated, so it becomes df(Residual) = n – (k+1) or df(Residual) = n – k – 1. It’s often easier just to use subtraction once you know the total and the regression degrees of freedom.
I am still confused with DF , suppose if we have a one independent variable in regression so what is the degrees of freedom in that case and why we use it . It would help me if you reply .
Jim I completed an 30 day online challenge project which had people do a pre and post test. I did this through Facebook and created a FB page. I had 15 people complete the pre test before the challenge began. Educational units and information were provided to complete the challenge over the next 30 days. unfortunately post challenge I only had four people do the post test. I tried and begged them to take the post test on the qualtrics link but never did. Since only 4 of the 15 completed the challenge what statistical analysis can I use in this case? I was originally prepared to do a Paired t-test but not any more. Any suggestions?
HI Aadya,
My understanding is that because there is only one z distribution, there is are no degrees of freedom associated with a z-test statistic.
or if n = 1, the best estimate for where the population mean is at that single sample value available. Therefore one independent information is available which gives one degree of freedom to estimate as parameter, the mean.
While we cannot obtain an estimate for the spread since a sample of size 1 does not vary, no variance, therefore no standard deviation. But, since it is not known from the sample whether the population has a large or narrow spread, we don’t have any information. So the standard deviation is undefined and its d.f. is zero.
I may be having some confusions here, most grateful if you could help please.
The formula for the number of degrees of freedom is:
no. of observations – no. of independent variables – 1 (d.f. = n – k – 1),
so in the regression output, how come the error degrees of freedom is 26 (28-2=26) and not 27 (28-2-1=27)?
Hi Jim,
Thanks a lot for this helpful explanation. I had a doubt – why don’t we use degrees of freedom in a z-test the way we use it in a t-test?(sorry, if this is a silly question but I was not able to figure this out)
Hi, Jim,
I found your explanation about df is very helpful.
You wrote “Degrees of freedom encompasses the notion that the amount of independent information you have limits the number of parameters that you can estimate”
My understanding is that if n=1 (df=0), no parameter can be estimated; if n=2 (df=1), then we can estimate a mean, variance (SD), correlation, etc.. Am I right?
Jackson
Dear i am confused that degree pf freedom tells us the no of observation or on some sites they said no of independent variables required to estimate the relationship.
in terms of P value as well when p-value is less than 0.05 than it means null hypothesis is false or true and we reject the null hypothesis . if its zero that means there is no relationship between variables .
p value tells the relationship between x and y or between independent variables (y).
GLAD IF YOU HELP ME
Hi Tarun,
As I write in this post, degrees of freedom represent the number of independent pieces of data. In regression modeling, you do incorporate the number of IVs into calculating the error degrees of freedom. As I show in this post, the method for calculating degrees of freedom changes based on the context. However, the underlying principle is that it represents the amount of independent data values that your are using to estimate the value of a population parameter.
I think you might have a fundamental misunderstanding about p-values. A p-value of zero (which technically is not possible but it can appear that way thanks to rounding) does not indicate there is no relationship. P-values represent the strength of the evidence that your sample provides against the null hypothesis. Please read this post of mine about how to interpret p-values. If after reading that post you have more questions, please post them in the comments section of that post.
I hope that helps!
Dear Jim, thank you very much for the elaboration, it helps a lot! However i do have difficulties making the connection between the degrees of freedom and the actual computing of the parameters. For example for calculating the variance i do understand that the quadratic difference of the last datapoint is determined beforehand by the other data. But we still add it up with all the other quadratic differences.. if we then want to take the mean of those quadratic differences it would still make sense to me to divide by n since we added up n different quadratic differences even though the last one was predetermined by the others… could you help me find out where i make a mistake in my reasoning?
Thank you again for this amazing blog post!
Best regards
Moritz
Hi Jim,
Thank you for your helpful explanation of degrees of freedom!
I am planning to run a linear mixed effects model containing the following explanatory variables: Treatment (n=4) * Genotype (n=48) + Source Location (4) + (1 | Unit). Unit is a random effect and n= 24 Units.
I assume that I would calculate the number of degrees of freedom in these variables as (3 X 47) + 3 + 23 = 167. I have 576 samples, so the total error degrees of freedom would be 576 – 167 = 409. Please let me know if this is correct, or if I am thinking about it incorrectly.
If my calculation is correct, is 409 a sufficient number of error degrees of freedom? What would be the minimum that would give me enough power (in case I wish to add more explanatory variables)?
Thank you.
Sincerely,
Carrie
Hi Carrie,
Calculating the DF for a linear mixed effects model is fairly complicated and even difficult for statistical software to calculate. That’s why you might not obtain p-values for mixed effects models. Some software calculates approximate DF and provide estimated p-values. Consequently, it’s tricky for me to say whether you have a sufficient sample size.
On the one hand, you have a good number of observations. However, on the other hand, you also have categorical (nominal) variables that have many levels, which eat up a ton of DF! My inclination is that, yes, you do have a sufficient number of observations. It being a mixed effects model does complicate it a bit but you probably have a somewhat small sample size. It might be a bit on the low side and you might have somewhat low power. Of course, the size of the effect is also an issue! I wouldn’t add too many additional variables, particularly if they are categorical variables with a large number of levels.
In short, I think it’s a little low on the sample size but probably not unusable. Usually you’d want ~10 subjects per DF used. Again, DF are a bit difficult to calculate for mixed effects models. However, as the DF increases, you don’t always need to add 10 subjects for each one, it diminishes. If we use the linear model DF, you’ve got ~3.5 subjects per DF. Probably lower than ideal in terms of power but the estimates should largely be unbiased.
Hi Jim,
I find the discussion about df very informative. In my study, I found different df values in t-tests of the same sample size (with different t-tests vary in values only). Kindly, please help in understanding this.
I found this discussions are more use full to me because I am Naive to statistics. But try some.
Dear Dr. Jim do we consider DF both in parametric and non parametric statistic.
Thanks
Hi, thanks for the great question. The answer is both yes and no! Hey, that’s statistics for you, right?
It depends on the nonparametric test. For example, the Mann Whitney test doesn’t use degrees of freedom.
However, the Kruskal Wallis uses DF because its test statistic approximates the chi-square distribution.
Hi Jim, thank you for further explaining. I get the idea that unknowns are free to vary until the very last one. The part I’m having trouble with is “imagine you know the mean”.
If we know the mean, then by definition we must know its components — how else could we have arrived at the mean? If I have 2 chimps in my zoo, and chimp A weighs 40 kg while chimp B weighs 60 kg, then on average they must weigh 50 kg. All values are fixed by reality.
But, of course if we’re saying that all chimps in the world weigh a theoretical 50 kg, then if it turns out that chimp A actually weighs 50 kg, then chimp B must theoretically weigh 50 kg (even though we know it really weighs 60 kg). Is this the idea? That the mean is a presupposed universal value based on prior knowledge? In other words, are we taking the global mean based on studies 1, 2, 3, …., 99 and applying it to study 100?
Thought I’d have one more go, but accepting and moving on may be the right move at this juncture!
Kevin
Hi Kevin,
The key concept is independent pieces of information. While the explanation might not totally be intuitive, it illustrates the general idea. The approach I take is a fairly standard one, but I’m trying to think of a better way to explain it.
It’s not based on presupposing prior knowledge, although I see how the explanation confuses things in that regard. But, when you’re estimating something, such as a mean, with the first values you uncover, the mean can still be anything. But, once you get to the final value, you can use algebra to calculate it using the mean–hence it is not an independent value. Of course, in the real world, you’re not going to know the mean before you calculate it using all the values. But, the 100% dependency still exists even though you can’t really use this method without prior knowledge. The example tries to show this underlying dependency.
I’m not sure if that helps any. I’ll think about it some more!
Jim
Hi Jim,
I also share Surya’s confusion. If, as you say, sample values are revealed, then doesn’t this imply that the mean must also be revealed? But here we talk about mean as if we have foreknowledge of its value. Is there a different explanation you can provide? Or is this something I should just accept, and move on?
Many thanks,
Kevin
Hi Kevin,
I’d never want to say that you should just accept something and move on! But, DF is a particularly slippery concept.
Focus on the key concept behind degrees of freedom. It is a count of the number of independent pieces of information. Focus particularly on the notion of “independent.”
Imagine you know the mean, and you keep revealing the actual observations one by one. At first, you can reveal an observation, and it doesn’t limit the potential values of the remaining observations. You can’t predict them using the available information–they’re truly independent. You get down to the last two unknown observed values. Despite there just being two unknowns, you still have absolutely zero ability to predict their values. However, once you reveal one more, you have a 100% ability to predict the final value. At that point, you are revealing one value yet you are learning two values. Hence, those two observations are not independent. Consequently, in the count of independent observations (aka DF), you need to subtract one (n – 1).
I hope that helps a bit at least!
what role of degree of freedom statistics in psychological research?
Hi Jim,
I’ve been going crazy trying to find the answer to this question – maybe you can help. Why is that the population variance doesn’t also get divided by N-1? It too depends on the population mean in order to be calculated correctly, so therefore the nth member of the population should not have freedom to vary, yet population variance is calculated by dividing by N. Please help, thanks!
Hi Nathaniel,
If have the measurements for an entire population, or you just want the variance for a sample, then you don’t need to divide by N-1 because in those cases you are not using it as an estimate. However, if you are working with a sample and want to use it to estimate the population variance, you do need to divide by N-1.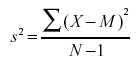
I hope this helps!
Hi Jim,
In the above post, the mean and 9 numbers are known ..so the DF is 9.I understood that.
My question is… How can we know the mean of 10 numbers in the first place if we do not know what is the 10th value.. Please clarify
Hi again Surya!
DF is a tricky concept. It is a bit weird but the idea is that the mean exists and the sample exists. You don’t know the values if haven’t calculated them, but as the sample values are revealed, the constraints on the remaining values increases. For that final observation, it must be on particular value and is no longer free to vary. There’s a 100% dependence of that last value on the value of the mean. In practice, you won’t go through that process, but it is important to build it into statistical tests because it reflects those underlying constraints.
Most grateful Sir.
Dear Dr Frost,
Thanks so much for this surgical explanation of the degrees of freedom. My understanding from your presentation is that the general rule for determining DF is the (R-1)(C-1) formula.
I have a 3×3 table as below:
AA AB BB Totals
Low
Mid
High
Totals
Here the number of rows=3 and columns=3
Thus, (3-1)(3-1)=(2)(2) = 4 DF.
Sir, am I right?
Kind regards
Wisdom
Hi Wisdom,
Yes, you are absolutely correct! Your 3X3 table has 4 degrees of freedom.
Dear Jim
Hi
I am sorry to bother you. I have a problem to describe the results below by degrees of freedom f.
Is it possible for helping me.
thanks.
x <- 1:20
true.y <- 2*x + 5
amt.noise <- 30
y <- true.y + amt.noise*rnorm(length(x))
cor.test(x,y)
# Pearson's product-moment correlation
#
# data: x and y
# t = -0.455, df = 18, p-value = 0.65
# alternative hypothesis: true correlation is not equal to 0
# 95 percent confidence interval:
# -0.52434 0.35260
# sample estimates:
# cor
# -0.10655
Hi Jim, just want to say thanks for providing a great and easy to understand resource for all of us who struggle to understand statistics! Much appreciated
You’re very welcome, Rob. I appreciate the kinds words too!
Hi Dr Jim,
I really appreciate your reply. It is really a great one.
Some articles do mentioned that we shall use interpolation method to find the t-value if it is not given in the table. But none discuss like what you have explained which can convince us to use the lower DF instead of using the standard rounding rules.
Thanks a lot Dr JIm.
Thanks Dr Jim for the reply.
But I have another question. Is the standard rounding rules can be used for F-table as well?
I have read a statistics textbook about finding the F-value which is not given in the table.
The author wrote: “When the degree of freedom values cannot be found in the table, the closed value of the smaller side should be used. For example, if d.f.N =14, this value is between the given table values of 12 and 15, therefore 12 should be used, to be on the safe side.”
May I have your opinion and what does it means safe side?
Thanks again.
Hi, so that’s a good point to consider, although it’s not always crucial, but one that I ultimately agree with.
What the author means by “safe side” is to pick the DF that requires stronger evidence to be statistically significant. For any given test statistic distribution (t-values, F-values, etc), if you can’t pick the exact DF from a table that you require, you should pick the DF that requires stronger evidence. For a test statistic, this is equivalent to picking the DF that is associated with a larger absolute value of the statistic–and that means choosing a lower DF.
In other words, you are in a situation where you need to make a choice because you can’t use the exactly correct value. The choice you make should require stronger evidence rather than weaker evidence to be statistically significant. That is “being safe.” It’s equivalent to lowering alpha from 5% to, say, 4.95%. You wouldn’t want to go the other direction and raise it to 5.05%
To be honest, it has been decades since I’ve thought about the practical realities of using tables given the use of statistical software. But, you raise an excellent point. In some cases, such as how I described 39 DF for the t-distribution, the difference is minute. You have to go out three decimal places to see a difference.
Additionally, hypothesis test results that are borderline significant (right around p = 0.05 when alpha = 0.05) are not particularly strong results. To see why, read my post about correctly interpreting p-values. Near the end of that post, I discuss strength of evidence. In a nutshell, I would not consider results with a p-value of 0.049 to be any stronger than 0.051. In either case, both results are fairly weak evidence to build a case on. Changing the DF affects these borderline cases. So, this approach of choosing lower DF requires “stronger” evidence to be significant–but borderline cases still don’t constitute strong evidence when you use the typical significance level of 0.05.
However, I do agree with the approach of choosing the DF that requires stronger evidence to produce statistically significant results. If you have to make a choice, make a choice in the direction of requiring stronger evidence. That approach indicates choosing the lower DF. Thanks for raising this issue! It was good to think through this!
Hi Dr Jim,
How do I find values not given in t-distribution?
I am using Statistical Table “Statistical Tables – J.A. Barnes|J. Murdoch – Macmillan International”, let say i wanted to find the t-value for alpha=0.05 with the degree of freedom 39. The table just provided the degrees of freedom for 30 and 40. Which one shall I choose?
What is the general rule for this problem? Either round up the degree of freedom or round down?
Thanks
Hi,
In the t-distribution, after you get past about 30 df, the differences between the t-values for different probabilities become miniscule. You often have to go out to three decimal places before you’ll find a difference in the t-values.
Consequently, you won’t be too far off using the standard rounding rules: rounding up for >= 5 and rounding down for < 5. In your case, I'd use 40. You can also use a more precise table of t-values, such as this one that lists 39 df specifically.
I hope this helps!
Thanks a lot . your explanation makes the job easier even for us who are not good in math and stats
Hi Edson, you’re very welcome. I’m glad it has helped!
Thanks Jim, I have probably found the first person with such clear basics. Hope to learn much more with you.
Hi Eajaz, thanks so much for the kind words! You made my day because I strive to find ways to teach statistics using easy to understand language!
Jim thanks for the core area in stat that you always state. I dwnld the hurd-0.9.tar.gz ..is it the right file? if not, could you please suggest which one is right and which app file has to run? thanks.
Hi Indranil, I’m not sure which file you’re referring to? Are you referring to the PSPP software? If you, I believe the correct file for Windows is pspp-20170909-daily-64bits-setup.exe. That is a file you can run to install the program.
Many thanks for such valuable knowledge sharing
My pleasure, Ali!
Very Very informative. Thank you very much.
Hi Arindam, you’re very welcome! I’m glad it was helpful!
And also we are confused in the diference between sample size and degree of freedom……
Sample size is the number of data points in your study. Degrees of freedom are often closely related to sample size yet are never quite the same. The relationship between sample size and degrees of freedom depends on the specific test. Hypothesis tests actually use the degrees of freedom in the calculations for statistical significance. Typically, DF define the probability distribution of the test statistic.
Dear sir,plz tell me that what is the diference between statistic and test statistic ?
Hi Salman,
A statistic is a piece of information based on data. For example, the crime rate, median income, mean height, etc.
A test statistic is a statistic that summarizes the sample data and is used in hypothesis testing to determine whether the results are statistically significant. The hypothesis test takes all of the sample data, reduces it to a single value, and then calculates probabilities based on that value to determine significance. For more information about how test statistics work, read my posts about t-values and F-values. Both of those are test statistics.
I hope this helps!
The minitab software you are using is free or paid…if it is free please provide me its link… thank you
Hi Akhilesh, Minitab is not free. However, if you’re looking for free statistical software, I recommend PSPP, which is freeware (fully functional, no time limits) that is very similar to SPSS. Download PSPP here.
The topic clearity is in very good format. But please explain this through R programming . Do that we can feel confidence while prediction.
Hi Dhruv, I’m glad you found the topic helpful! My blog is designed to teach statistical concepts, analyses, interpretation, etc rather than teaching a specific software package. You’ll find that degrees of freedom is inherent to statistics regardless of the software you use. The software package can supply the documentation that describes how to obtain the specific results that you need.
Wow. Superb. Thank you so much. All I can do.
thanks Dr jim so nice concept
Thank you!
in simple words we can say that, the total sample size minus the number of parameters to be estimated in a series is called D.F, am i right dear Jim? which software you have used for graphs?
Hi Muhammad! Yes, that’s a good general sense of the term. However, it’s not always exactly correct. For instance, take a look at the chi-square examples. I used Minitab software for the graphs.
Best wishes to you!
Jim
thank you Jim, I always find your article is of great value to me.
You’re very welcome, Teng. I’m very happy to hear that you find them to be helpful!