What is Goodness of Fit?
Goodness of fit evaluates how well observed data align with the expected values from a statistical model.

When diving into statistics, you’ll often ask, “How well does my model fit the data?” A tight fit? Your model’s excellent. A loose fit? Maybe reconsider that model. That’s the essence of goodness of fit. More specifically:
- A high goodness of fit indicates the observed values are close to the model’s expected values.
- A low goodness of fit shows the observed values are relatively far from the expected values.
A model that fits the data well provides accurate predictions and deeper insights, while a poor fit can lead to misleading conclusions and predictions. Ensuring a good fit is crucial for reliable outcomes and informed actions.
A goodness of fit measure summarizes the size of the differences between the observed data and the model’s expected values. A goodness of fit test determines whether the differences are statistically significant. Moreover, they can guide us in choosing a model offering better representation. The appropriate goodness of fit measure and test depend on the setting.
In this blog post, you’ll learn about the essence of goodness of fit in the crucial contexts of regression models and probability distributions. We’ll measure it in regression models and learn how to test sample data against distributions using goodness of fit tests.
Goodness of Fit in Regression Models
In regression models, understanding the goodness of fit is crucial to ensure accurate predictions and meaningful insights; here, we’ll delve into key metrics that reveal this alignment with the data.
A regression model fits the data well when the differences between the observed and predicted values are small and unbiased. Statisticians refer to these differences as residuals.
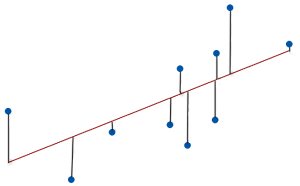
As the goodness of fit increases, the data points move closer to the model’s fitted line.
R-squared (R²)
R-squared is a goodness of fit statistic for linear regression models. It measures the percentage of the dependent variable variation the model explains using a convenient 0 – 100% scale.
R-squared evaluates the spread of the data around the fitted regression line. For a data set, higher R-squared values indicate smaller differences between the sample data and the fitted values.


The model with the wider spread has an R-squared of 15% while the one with the narrower spread is 85%.
Think of R² as the percentage that explains the variation. Higher R²? Better fit.
- High R²: Your model captures a lot of variation.
- Low R²: The model doesn’t explain much of the variance.
Remember, it’s not the sole indicator. High R² doesn’t always mean a perfect model!
Learn more about How to Interpret R-squared and Independent vs Dependent Variables.
Standard Error of the Regression (S)
This standard error of the regression is a goodness of fit measure that provides the typical size of the absolute difference between observed and predicted values. S uses the units of the dependent variable (DV).
- Small S: Predictions are close to the data values.
- Large S: Predictions deviate more.
Suppose your model uses body mass index (BMI) to predict the body fat percentage (the DV). Consequently, if your model’s S is 3.5, then you know that its predicted values are typically 3.5% from the observed body fat percentage values.
However, don’t view it in isolation. Compare it with the dependent variable’s units for context.
Learn more about the Standard Error of the Regression.
Akaike’s Information Criterion (AIC)
The Akaike Information Criterion (AIC) is a goodness of fit measure that statisticians designed to compare models and help you pick the best one. The AIC value isn’t meaningful itself, but you’re looking for the model with the lowest AIC.
- Lower AIC: Your model is probably better (when comparing).
- Adjusts for complexity: Simpler models are preferred when they fit well.
Learn why you want a simpler model, which statisticians refer to as a parsimonious model: What is a Parsimonious Model? Benefits & Selecting.
There are other goodness-of-fit statistics, like Adjusted R² and the Bayesian Information Criteria (BIC). Each has its unique strength. But for a start, focus on these three.
Goodness of Fit for Probability Distributions
Sometimes, your statistical model is that your data follow a particular probability distribution, such as the normal, lognormal, Poisson, or some other distribution. You want to know if your sample’s distribution is consistent with the hypothesized distribution. Learn more about Probability Distributions.
Why?
Because many statistical tests and methods rest on distributional assumptions.
For instance, t-tests and ANOVA assume your data are normal. Conversely, you might expect a Poisson distribution if you’re analyzing the number of daily website visits. Capability analysis in the quality arena depends on knowing precisely which distribution your data follow.
Enter goodness of fit tests.
A goodness of fit test determines whether the differences between your sample data and the distribution are statistically significant. In this context, statistical significance indicates the model does not adequately fit the data. The test results can guide the analytical procedures you’ll use.
I’ll cover two of the many available goodness of fit tests. The Anderson-Darling test works for continuous data, and the chi-square goodness of fit test is for categorical and discrete data.
Anderson-Darling Test
The Anderson-Darling goodness of fit test compares continuous sample data to a particular probability distribution. Statisticians often use it for normality tests, but the Anderson-Darling Test can also assess other probability distributions, making it versatile in statistical analysis.
The hypotheses for the Anderson-Darling test are the following:
- Null Hypothesis (H₀): The data follow the specified distribution.
- Alternative Hypothesis (HA): The data do not follow the distribution.
When the p-value is less than your significance level, reject the null hypothesis. Consequently, statistically significant results for a goodness of fit test suggest your data do not fit the chosen distribution, prompting further investigation or model adjustments.
Imagine you’re researching the body fat percentages of pre-teen girls, and you want to know if these percentages follow a normal distribution. You can download the CSV data file: body_fat.
After collecting body fat data from 92 girls, you perform the Anderson-Darling Test and obtain the following results.

Because the p-value is less than 0.05, reject the null hypothesis and conclude the sample data do not follow a normal distribution.
Learn how to identify the distribution of this bodyfat dataset using the Anderson-Darling goodness of fit test.
Use my free online Normality Test Calculator to determine whether your data follow a normal distribution!
Chi-squared Goodness of Fit Test
The chi square goodness of fit test reveals if the proportions of a discrete or categorical variable follow a distribution with hypothesized proportions.
Statisticians often use the chi square goodness of fit test to evaluate if the proportions of categorical outcomes are all equal. Or the analyst can list the proportions to use in the test. Alternatively, this test can determine if the observed outcomes fit a discrete probability distribution, like the Poisson distribution.
This goodness of fit test does the following:
- Calculates deviations: Uses the squared difference between observed and expected.
- P-value < 0.05: Observed and expected frequencies don’t match.
Imagine you’re curious about dice fairness. You roll a six-sided die 600 times, expecting each face to come up 100 times if it’s fair.
The observed counts are 90, 110, 95, 105, 95, and 105 for sides 1 through 6. The observed values don’t matched the expected values of 100 for each die face. Let’s run the Chi-square goodness of fit test for these data to see if those differences are statistically significant.

The p-value of 0.700 is greater than 0.05, so you fail to reject the null hypothesis. The observed frequencies don’t differ significantly from the expected frequencies. Your sample data do not support the claim that the die is unfair!
To explore other examples of the chi square test in action, read the following:
Goodness of fit tells the story of your data and its relationship with a model. It’s like a quality check. For regression, R², S, and AIC are great starters. For probability distributions, the Anderson-Darling and Chi-squared goodness of fit tests are go-tos. Dive in, fit that model, and let the data guide you!

Jim, I have a pricing curve model to estimate the curvature of per unit cost (decrease) as purchased quantity increases. It follows the power law Y=Ax^B.
In my related log-log linear regression, the average residual is $0.00, which makes sense because we kept the Y-intercept in the model. However, in the transformed model in natural units, the residuals no longer average $0.00. Why does that property not carry over to the Y=Ax^B form of regression?
As a side note, I have your book “Regression Analysis,” which I have read several times and learned quite a lot. I believe there are two similar errors in Chapter 13, not related to my question above.
On page 323, when transforming the fitted line in log units back to natural units, the coefficient A in Y=Ax^B should be the common antilog of 0.5758 or 3.7653. Similarly, on page 325, the coefficient A should be the common antilog of 1.879 or 75.6833. This can be visually checked for reasonableness by looking at the graph on page 325. If we look at the x-axis, say at x=1, it appears y should be slightly less than 100. If we evaluate the power expression Y=75.6833x^(-0.6383), the fitted value is 75.68, which seems to be what the graph predicts.
The relevant logarithmic identity is log(ab) = log(a) + log(b). The Y-intercept in the log-log linear model is necessarily in log units, not natural units.
Hi Robert,
Those are good questions.
I’m not exactly sure what is happening in your model but here are my top two possibilities.
When you transform data, especially using non-linear transformations like logarithms, the relationship between the variables can change. In the log-log linear regression, the relationship is linear, and the residuals (differences between observed and predicted values) average out to $0.00. However, when you transform back to the natural units using an exponential function, the relationship becomes non-linear. This non-linearity can cause the residuals to no longer average out to $0.00.
When you re-express the log-log model to its natural units form, there might be some approximation or rounding errors. These errors can accumulate and affect the average of the residuals.
As for the output in the book, that was all calculated by statistical software that I trust (Minitab). I’ll have to look deeper into what is going on, but I trust the results.